Chatbot Evaluation Quickstart
Learn to evaluate any multi-turn chatbot using deepeval - including QA agents, customer support chatbots, and even chatrooms.
Overview
Chatbot Evaluation is different from other types of evaluations because unlike single-turn tasks, conversations happen over multiple "turns". This means your chatbot must stay context-aware across the conversation, and not just accurate in individual responses.
In this 10 min quickstart, you'll learn how to:
- Prepare conversational test cases
- Evaluate chatbot conversations
- Simulate users interactions
Prerequisites
- Install
deepeval - A Confident AI API key (recommended). Sign up for one here.
Understanding Multi-Turn Evals
Multi-turn evals are tricky because of the ad-hoc nature of conversations. The nth AI output will depend on the (n-1)th user input, and this depends on all prior turns up until the initial message.
Hence, when running evals for the purpose of benchmarking we cannot compare different conversations by looking at their turns. In deepeval, multi-turn interactions are grouped by scenarios instead. If two conversations occur under the same scenario, we consider those the same.
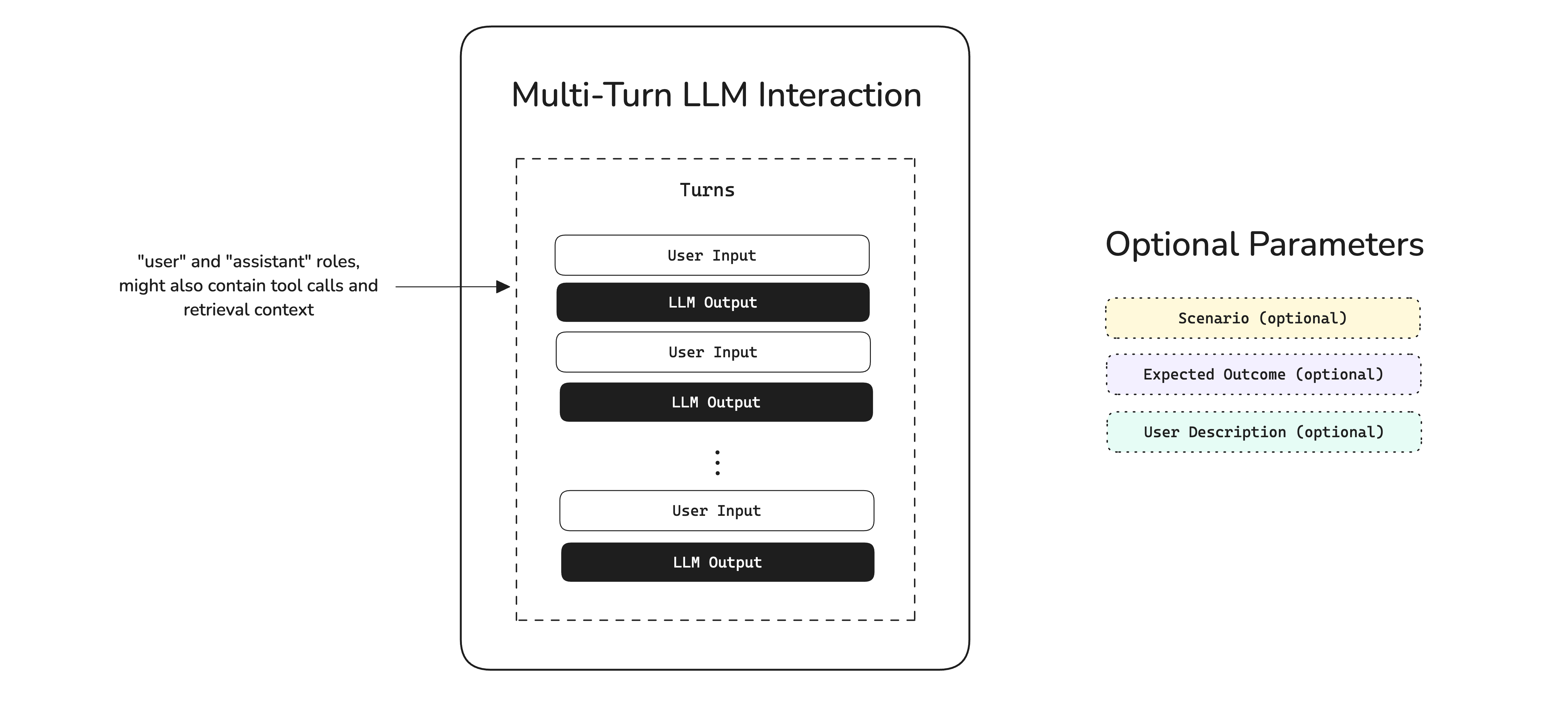
Run A Multi-Turn Eval
In deepeval, chatbots are evaluated as multi-turn interactions. In code, you'll have to format them into test cases, which adheres to OpenAI's messages format.
Create a test case
Create a ConversationalTestCase by passing in a list of Turns from an existing conversation, similar to OpenAI's message format.
from deepeval.test_case import ConversationalTestCase, Turn
test_case = ConversationalTestCase(
turns=[
Turn(role="user", content="Hello, how are you?"),
Turn(role="assistant", content="I'm doing well, thank you!"),
Turn(role="user", content="How can I help you today?"),
Turn(role="assistant", content="I'd like to buy a ticket to a Coldplay concert."),
]
)You can learn about a Turn's data model here.
Run an evaluation
Run an evaluation on the test case using deepeval's multi-turn metrics, or create your own using Conversational G-Eval.
from deepeval.metrics import TurnRelevancyMetric, KnowledgeRetentionMetric
from deepeval import evaluate
...
evaluate(test_cases=[test_case], metrics=[TurnRelevancyMetric(), KnowledgeRetentionMetric()])Finally run main.py:
python main.py🎉🥳 Congratulations! You've just ran your first multi-turn eval. Here's what happened:
- When you call
evaluate(),deepevalruns all yourmetricsagainst alltest_cases - All
metricsoutputs a score between0-1, with athresholddefaulted to0.5 - A test case passes only if all metrics passess
This creates a test run, which is a "snapshot"/benchmark of your multi-turn chatbot at any point in time.
View on Confident AI (recommended)
If you've set your CONFIDENT_API_KEY, test runs will appear automatically on Confident AI, which deepeval integrates with natively.
Working With Datasets
Although we ran an evaluation in the previous section, it's not very useful because it is far from a standardized benchmark. To create a standardized benchmark for evals, use deepeval's datasets:
from deepeval.dataset import EvaluationDataset, ConversationalGolden
dataset = EvaluationDataset(
goldens=[
ConversationalGolden(scenario="Angry user asking for a refund"),
ConversationalGolden(scenario="Couple booking two VIP Coldplay tickets")
]
)A dataset is a collection of goldens in deepeval, and in a multi-turn context this these are represented by ConversationalGoldens.
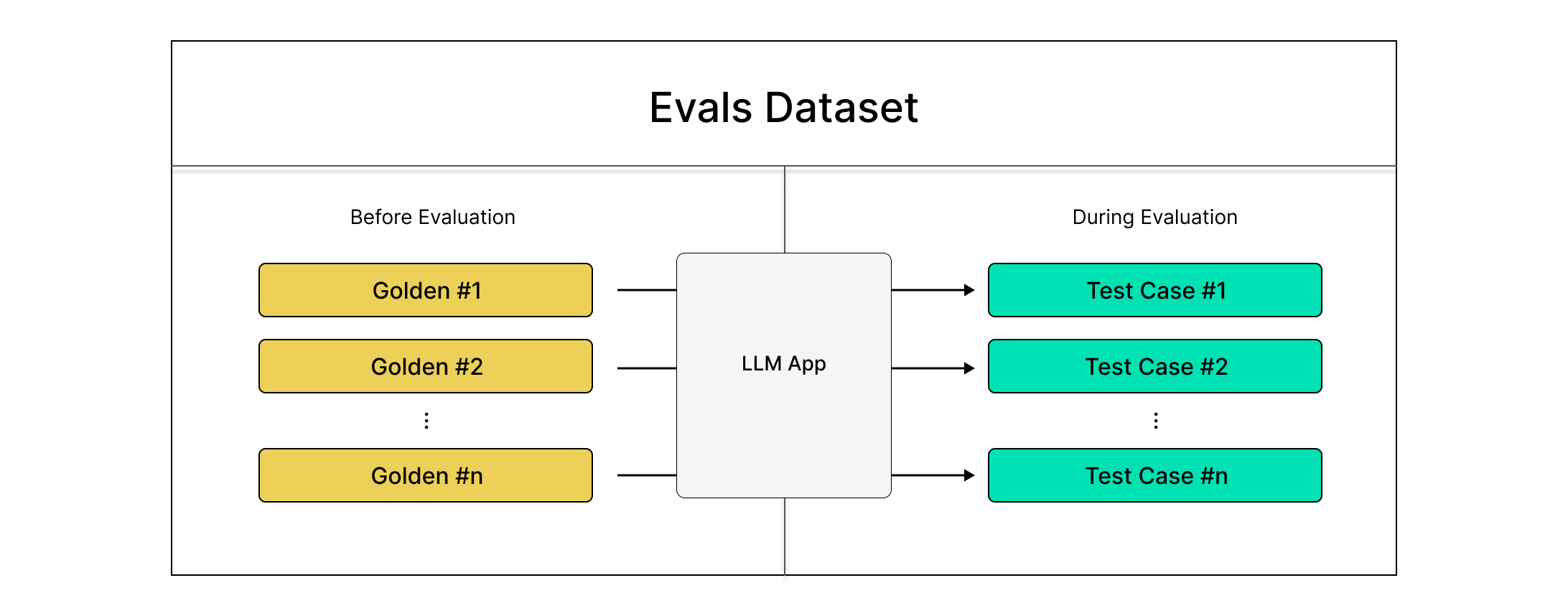
The idea is simple - we start with a list of standardized scenarios for each golden, and we'll simulate turns during evaluation time for more robust evaluation.
Simulate Turns for Evals
Evaluating your chatbot from simulated turns is the best approach for multi-turn evals, because it:
- Standardizes your test bench, unlike ad-hoc evals
- Automates the process of manual prompting, which can take hours
Both of which are solved using deepeval's ConversationSimulator.
Create dataset of goldens
Create a ConversationalGolden by providing your user description, scenario, and expected outcome, for the conversation you wish to simulate.
from deepeval.dataset import EvaluationDataset, ConversationalGolden
golden = ConversationalGolden(
scenario="Andy Byron wants to purchase a VIP ticket to a Coldplay concert.",
expected_outcome="Successful purchase of a ticket.",
user_description="Andy Byron is the CEO of Astronomer.",
)
dataset = EvaluationDataset(goldens=[golden])If you've set your CONFIDENT_API_KEY correctly, you can save them on the platform to collaborate with your team:
dataset.push(alias="A new multi-turn dataset")Wrap chatbot in callback
Define a callback function to generate the next chatbot response in a conversation, given the conversation history.
from deepeval.test_case import Turn
async def model_callback(input: str, turns: List[Turn], thread_id: str) -> Turn:
# Replace with your chatbot
response = await your_chatbot(input, turns, thread_id)
return Turn(role="assistant", content=response)from deepeval.test_case import Turn
from openai import OpenAI
client = OpenAI()
async def model_callback(input: str, turns: List[Turn]) -> str:
messages = [
{"role": "system", "content": "You are a ticket purchasing assistant"},
*[{"role": t.role, "content": t.content} for t in turns],
{"role": "user", "content": input},
]
response = await client.chat.completions.create(model="gpt-4.1", messages=messages)
return Turn(role="assistant", content=response.choices[0].message.content)from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
store = {}
llm = ChatOpenAI(model="gpt-4")
prompt = ChatPromptTemplate.from_messages([("system", "You are a ticket purchasing assistant."), MessagesPlaceholder(variable_name="history"), ("human", "{input}")])
chain_with_history = RunnableWithMessageHistory(prompt | llm, lambda session_id: store.setdefault(session_id, ChatMessageHistory()), input_messages_key="input", history_messages_key="history")
async def model_callback(input: str, thread_id: str) -> Turn:
response = chain_with_history.invoke(
{"input": input},
config={"configurable": {"session_id": thread_id}}
)
return Turn(role="assistant", content=response.content)from llama_index.core.storage.chat_store import SimpleChatStore
from llama_index.llms.openai import OpenAI
from llama_index.core.chat_engine import SimpleChatEngine
from llama_index.core.memory import ChatMemoryBuffer
chat_store = SimpleChatStore()
llm = OpenAI(model="gpt-4")
async def model_callback(input: str, thread_id: str) -> Turn:
memory = ChatMemoryBuffer.from_defaults(chat_store=chat_store, chat_store_key=thread_id)
chat_engine = SimpleChatEngine.from_defaults(llm=llm, memory=memory)
response = chat_engine.chat(input)
return Turn(role="assistant", content=response.response)from agents import Agent, Runner, SQLiteSession
sessions = {}
agent = Agent(name="Test Assistant", instructions="You are a helpful assistant that answers questions concisely.")
async def model_callback(input: str, thread_id: str) -> Turn:
if thread_id not in sessions:
sessions[thread_id] = SQLiteSession(thread_id)
session = sessions[thread_id]
result = await Runner.run(agent, input, session=session)
return Turn(role="assistant", content=result.final_output)from pydantic_ai.messages import ModelRequest, ModelResponse, UserPromptPart, TextPart
from deepeval.test_case import Turn
from datetime import datetime
from pydantic_ai import Agent
from typing import List
agent = Agent('openai:gpt-4', system_prompt="You are a helpful assistant that answers questions concisely.")
async def model_callback(input: str, turns: List[Turn]) -> Turn:
message_history = []
for turn in turns:
if turn.role == "user":
message_history.append(ModelRequest(parts=[UserPromptPart(content=turn.content, timestamp=datetime.now())], kind='request'))
elif turn.role == "assistant":
message_history.append(ModelResponse(parts=[TextPart(content=turn.content)], model_name='gpt-4', timestamp=datetime.now(), kind='response'))
result = await agent.run(input, message_history=message_history)
return Turn(role="assistant", content=result.output)Simulate turns
Use deepeval's ConversationSimulator to simulate turns using goldens in your dataset:
from deepeval.conversation_simulator import ConversationSimulator
simulator = ConversationSimulator(model_callback=chatbot_callback)
conversational_test_cases = simulator.simulate(goldens=dataset.goldens, max_turns=10)Here, we only have 1 test case, but in reality you'll want to simulate from at least 20 goldens.
Click to view an example simulated test case
Your generated test cases should be populated with simulated Turns, along with the scenario, expected_outcome, and user_description from the conversation golden.
ConversationalTestCase(
scenario="Andy Byron wants to purchase a VIP ticket to a Coldplay concert.",
expected_outcome="Successful purchase of a ticket.",
user_description="Andy Byron is the CEO of Astronomer.",
turns=[
Turn(role="user", content="Hello, how are you?"),
Turn(role="assistant", content="I'm doing well, thank you!"),
Turn(role="user", content="How can I help you today?"),
Turn(role="assistant", content="I'd like to buy a ticket to a Coldplay concert."),
]
)Run an evaluation
Run an evaluation like how you learnt in the previous section:
from deepeval.metrics import TurnRelevancyMetric
from deepeval import evaluate
...
evaluate(conversational_test_cases, metrics=[TurnRelevancyMetric()])✅ Done. You've successfully learnt how to benchmark your chatbot.
Next Steps
Now that you have run your first chatbot evals, you should:
- Customize your metrics: Update the list of metrics based on your use case.
- Setup tracing: It helps you log multi-turn interactions in production.
- Enable evals in production: Monitor performance over time using the metrics you've defined on Confident AI.
You'll be able to analyze performance over time on threads this way, and add them back to your evals dataset for further evaluation.