AI Agent Evaluation Quickstart
Learn how to evaluate AI Agents using deepeval, including multi-agent systems and tool-using agents.
Overview
AI agent evaluation is different from other types of evals because agentic workflows are complex and consist of multiple interacting components, such as tools, chained LLM calls, and RAG modules. Therefore, it’s important to evaluate your AI agents both end-to-end and at the component level to understand how each part performs.
In this 5 min quickstart, you'll learn how to:
- Evaluate your agent end-to-end in CI/CD
- Evaluate individual components, inculding sub-agents, in your agent
How It Works
Agent evals in deepeval are powered by tracing:
- Instrument your agent once — with
@observeor a framework integration. - Every run emits a trace — with a span per component: LLM calls, tools, retrievers, sub-agents.
- Attach metrics where you want evals — the trace for end-to-end, individual spans for component-level.
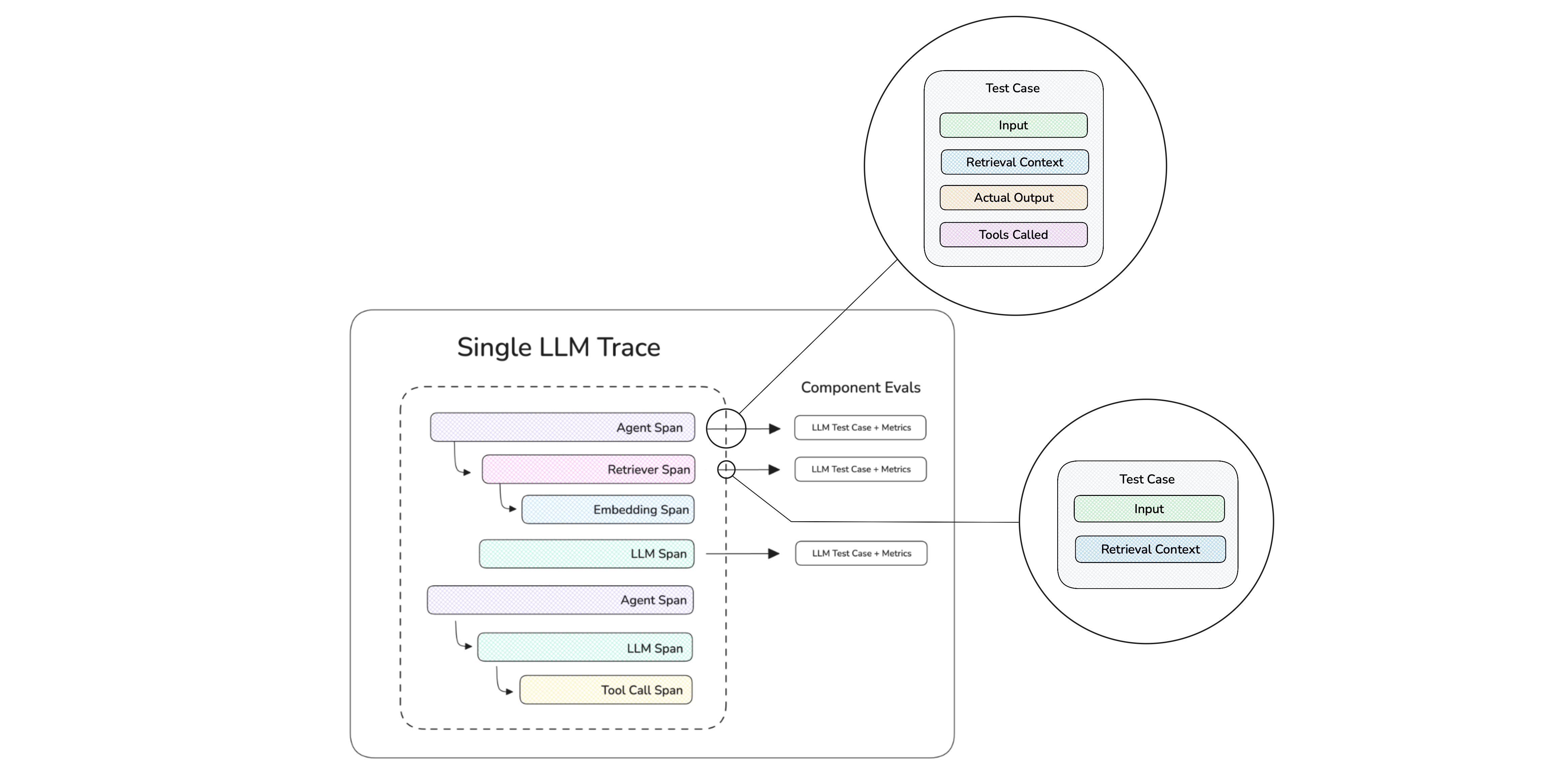
Test cases are built from traces automatically, and everything in this quickstart — CI/CD, evals_iterator(), sub-agents — runs on this one setup.
Installation
pip install -U deepeval[inspect]Do I need the [inspect] sub-module?
The [inspect] sub-module is optional and can bloat up deepeval's package size so we highly recommend that you don't install deepeval with [inspect] outside of dev environments.
You should also run deepeval login:
deepeval loginIt connects you to Confident AI so you can store results, annotate, and inspect evaluated agent traces on the cloud.
Unit Test Agents in CI/CD
The fastest way to start evaluating your agent is to unit test it. deepeval plugs into pytest via assert_test() and the deepeval test run command, so your agent evals run like any other test suite — locally in development, and on every push or PR.
Create a dataset
Datasets in deepeval store Goldens — the inputs you'll invoke your agent with at test time:
from deepeval.dataset import Golden, EvaluationDataset
goldens = [
Golden(input="What is your name?"),
Golden(input="Choose a number between 1 and 100"),
# ...
]
dataset = EvaluationDataset(goldens=goldens)from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.pull(alias="My Evals Dataset")from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.add_goldens_from_csv_file(
file_path="example.csv",
input_col_name="query",
)from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.add_goldens_from_json_file(
file_path="example.json",
input_key_name="query",
)Write your test file
Instrument your agent based on your tech stack, then parametrize a pytest test over your goldens and call assert_test(). Since your agent is traced, deepeval builds each test case automatically — no manual extraction of inputs and outputs:
import pytest
from deepeval import assert_test
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
from deepeval.tracing import observe, update_current_trace
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
@observe()
def my_ai_agent(query: str) -> str:
answer = "Pi rounded to 2 decimal places is 3.14."
update_current_trace(input=query, output=answer)
return answer
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_llm_app(golden: Golden):
my_ai_agent(golden.input)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Wrap your agent's top-level function with @observe and set the trace-level test case fields with update_current_trace(...). See LLM tracing for the full surface.
import pytest
from langchain.agents import create_agent
from deepeval import assert_test
from deepeval.integrations.langchain import CallbackHandler
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
agent = create_agent(
model="openai:gpt-4o-mini",
tools=[],
system_prompt="Answer math questions concisely.",
)
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_langchain_app(golden: Golden):
agent.invoke(
{"messages": [{"role": "user", "content": golden.input}]},
config={"callbacks": [CallbackHandler()]},
)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Pass deepeval's CallbackHandler to your agent's invoke method. See the LangChain integration for the full surface.
import pytest
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START, END
from deepeval import assert_test
from deepeval.integrations.langchain import CallbackHandler
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
llm = init_chat_model("openai:gpt-4o-mini")
def chatbot(state: MessagesState):
return {"messages": [llm.invoke(state["messages"])]}
graph = (
StateGraph(MessagesState)
.add_node(chatbot)
.add_edge(START, "chatbot")
.add_edge("chatbot", END)
.compile()
)
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_langgraph_app(golden: Golden):
graph.invoke(
{"messages": [{"role": "user", "content": golden.input}]},
config={"callbacks": [CallbackHandler()]},
)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Pass deepeval's CallbackHandler to your StateGraph's invoke method. See the LangGraph integration for the full surface.
import pytest
from deepeval import assert_test
from deepeval.openai import OpenAI
from deepeval.tracing import trace
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent (drop-in replace `from openai import OpenAI`)
client = OpenAI()
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_openai_app(golden: Golden):
with trace():
client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Answer in one short sentence."},
{"role": "user", "content": golden.input},
],
)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Drop-in replace from openai import OpenAI with from deepeval.openai import OpenAI — every completion call becomes an LLM span automatically. See the OpenAI integration for the full surface.
import pytest
from pydantic_ai import Agent
from deepeval import assert_test
from deepeval.integrations.pydantic_ai import DeepEvalInstrumentationSettings
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
agent = Agent(
"openai:gpt-5",
system_prompt="Answer in one short sentence.",
instrument=DeepEvalInstrumentationSettings(),
)
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_pydantic_ai_app(golden: Golden):
agent.run_sync(golden.input)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Pass DeepEvalInstrumentationSettings() to your Agent's instrument keyword. See the Pydantic AI integration for the full surface.
import pytest
from bedrock_agentcore import BedrockAgentCoreApp
from strands import Agent
from deepeval import assert_test
from deepeval.integrations.agentcore import instrument_agentcore
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
instrument_agentcore()
app = BedrockAgentCoreApp()
agent = Agent(model="amazon.nova-lite-v1:0")
@app.entrypoint
def invoke(payload):
result = agent(payload["prompt"])
return {"result": result.message}
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_agentcore_app(golden: Golden):
invoke({"prompt": golden.input})
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Call instrument_agentcore() before creating your AgentCore app — it also instruments Strands agents running inside AgentCore. See the AgentCore integration for the full surface.
import pytest
from strands import Agent
from strands.models.openai import OpenAIModel
from deepeval import assert_test
from deepeval.integrations.strands import instrument_strands
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="Help me return my order.")])
# 2. Instrument your agent
instrument_strands()
agent = Agent(
model=OpenAIModel(model_id="gpt-4o-mini"),
system_prompt="You are a helpful assistant.",
)
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_strands_agent(golden: Golden):
agent(golden.input)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Call instrument_strands() before creating or invoking your agent (for AgentCore-hosted Strands, use the AgentCore tab). See the Strands integration for the full surface.
import pytest
from deepeval import assert_test
from deepeval.anthropic import Anthropic
from deepeval.tracing import trace
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent (drop-in replace `from anthropic import Anthropic`)
client = Anthropic()
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_anthropic_app(golden: Golden):
with trace():
client.messages.create(
model="claude-sonnet-4-5",
max_tokens=1024,
system="Answer in one short sentence.",
messages=[{"role": "user", "content": golden.input}],
)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Drop-in replace from anthropic import Anthropic with from deepeval.anthropic import Anthropic — every messages.create(...) call becomes an LLM span automatically. See the Anthropic integration for the full surface.
import asyncio
import pytest
from llama_index.llms.openai import OpenAI
from llama_index.core.agent import FunctionAgent
import llama_index.core.instrumentation as instrument
from deepeval import assert_test
from deepeval.integrations.llama_index import instrument_llama_index
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
instrument_llama_index(instrument.get_dispatcher())
agent = FunctionAgent(
tools=[],
llm=OpenAI(model="gpt-4o-mini"),
system_prompt="Answer math questions concisely.",
)
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_llamaindex_app(golden: Golden):
asyncio.run(agent.run(golden.input))
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Register deepeval's event handler against LlamaIndex's instrumentation dispatcher. See the LlamaIndex integration for the full surface.
import pytest
from agents import Runner, add_trace_processor
from deepeval import assert_test
from deepeval.openai_agents import Agent, DeepEvalTracingProcessor
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
add_trace_processor(DeepEvalTracingProcessor())
agent = Agent(
name="math_agent",
instructions="Answer math questions concisely.",
)
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_openai_agents_app(golden: Golden):
Runner.run_sync(agent, golden.input)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Register DeepEvalTracingProcessor once, then build your agent with deepeval's Agent shim. See the OpenAI Agents integration for the full surface.
import asyncio
import pytest
from google.adk.agents import LlmAgent
from google.adk.runners import InMemoryRunner
from google.genai import types
from deepeval import assert_test
from deepeval.integrations.google_adk import instrument_google_adk
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
instrument_google_adk()
agent = LlmAgent(model="gemini-2.0-flash", name="assistant", instruction="Answer math questions concisely.")
runner = InMemoryRunner(agent=agent, app_name="deepeval-google-adk")
async def run_agent(prompt: str) -> str:
session = await runner.session_service.create_session(app_name="deepeval-google-adk", user_id="demo-user")
message = types.Content(role="user", parts=[types.Part(text=prompt)])
async for event in runner.run_async(user_id="demo-user", session_id=session.id, new_message=message):
if event.is_final_response() and event.content:
return "".join(part.text for part in event.content.parts if getattr(part, "text", None))
return ""
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_google_adk_app(golden: Golden):
asyncio.run(run_agent(golden.input))
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Call instrument_google_adk() once before building your LlmAgent. See the Google ADK integration for the full surface.
import pytest
from crewai import Task
from deepeval import assert_test
from deepeval.integrations.crewai import instrument_crewai, Crew, Agent
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
instrument_crewai()
tutor = Agent(
role="Math Tutor",
goal="Answer math questions accurately and concisely.",
backstory="An experienced tutor who explains simple math clearly.",
)
task = Task(
description="{question}",
expected_output="Pi rounded to 2 decimal places is 3.14.",
agent=tutor,
)
crew = Crew(agents=[tutor], tasks=[task])
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_crewai_app(golden: Golden):
crew.kickoff({"question": golden.input})
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Call instrument_crewai() once, then build your crew with deepeval's Crew and Agent shims. See the CrewAI integration for the full surface.
There are ONE mandatory and ONE optional parameter for assert_test() in this mode:
golden: theGoldenyou pass in through your test function.- [Optional]
metrics: a list ofBaseMetrics that you wish to run on your trace (aka. end-to-end evals).
Run with deepeval test run
deepeval test run test_llm_app.pyEvery test run is also saved locally. Run deepeval inspect to view your agent's full execution trace — per-span scores and metric reasons included — right in your terminal:
deepeval inspect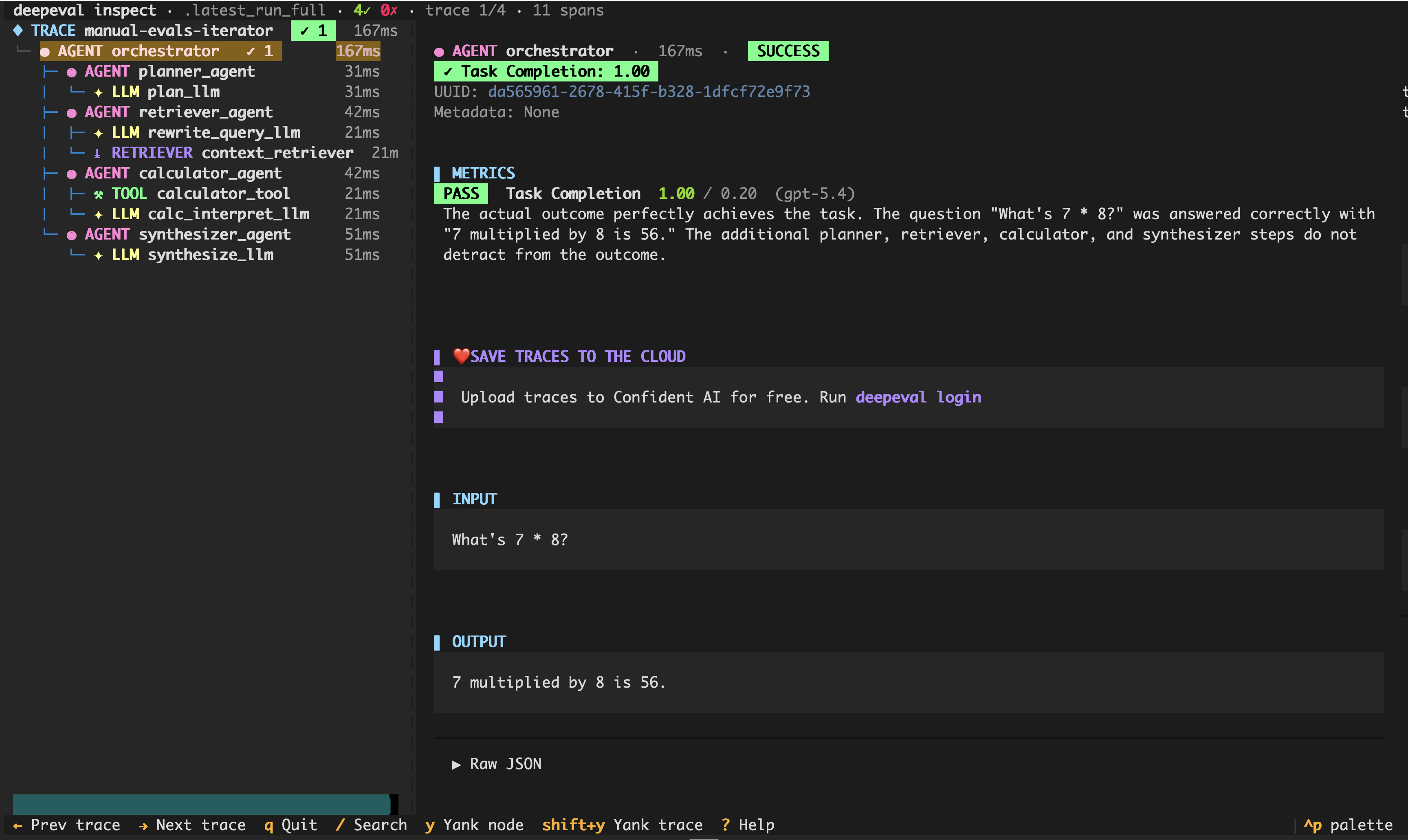
This is what the [inspect] sub-module you installed earlier is for — full details in the deepeval inspect reference.
Add it to your CI/CD pipeline
Drop deepeval test run into a .yml to unit test your agent on every push or PR. This example uses poetry for installation and OPENAI_API_KEY as your LLM judge to run evals locally. Add CONFIDENT_API_KEY to send results to Confident AI.
name: AI Agent `deepeval` Tests
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
steps:
- name: Checkout Code
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: "3.10"
- name: Install Poetry
run: |
curl -sSL https://install.python-poetry.org | python3 -
echo "$HOME/.local/bin" >> $GITHUB_PATH
- name: Install Dependencies
run: poetry install --no-root
- name: Run `deepeval` Unit Tests
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
CONFIDENT_API_KEY: ${{ secrets.CONFIDENT_API_KEY }}
run: poetry run deepeval test run test_llm_app.py✅ Done. Failing metrics now fail the build, so agent regressions get caught before they ship.
Evaluate Agents with evals_iterator()
Unit testing is built for CI/CD, but during development you'll usually iterate on your agent in a script or notebook. dataset.evals_iterator() does this in a plain for loop — it yields each golden, builds a test case from the captured trace, scores your metrics, and bundles traces + scores into one test run.
Reuse your dataset
evals_iterator() works off the same EvaluationDataset of goldens you created earlier:
from deepeval.dataset import Golden, EvaluationDataset
goldens = [
Golden(input="What is your name?"),
Golden(input="Choose a number between 1 and 100"),
# ...
]
dataset = EvaluationDataset(goldens=goldens)Trace your agent and run the loop
Pick your tech stack below and loop with evals_iterator(metrics=[...]) — each captured trace gets scored as one end-to-end test case.
Every integration comes in an Async and a Sync flavor:
- Async (default, fastest): wrap each invocation in
asyncio.create_task(...)+dataset.evaluate(task)so goldens run concurrently. - Sync: pass
AsyncConfig(run_async=False)to run one golden at a time — handy for debugging, rate-limited providers, or Jupyter event-loop quirks.
Wrap the top-level function with @observe and call update_current_trace(...) to set the trace-level test case fields:
import asyncio
from deepeval.tracing import observe, update_current_trace
from deepeval.metrics import TaskCompletionMetric
...
@observe()
async def my_ai_agent(query: str) -> str:
answer = "..." # await your LLM call here
update_current_trace(input=query, output=answer)
return answer
for golden in dataset.evals_iterator(metrics=[TaskCompletionMetric()]):
task = asyncio.create_task(my_ai_agent(golden.input))
dataset.evaluate(task)from deepeval.evaluate import AsyncConfig
from deepeval.tracing import observe, update_current_trace
from deepeval.metrics import TaskCompletionMetric
...
@observe()
def my_ai_agent(query: str) -> str:
answer = "..." # call your LLM here
update_current_trace(input=query, output=answer)
return answer
for golden in dataset.evals_iterator(
metrics=[TaskCompletionMetric()],
async_config=AsyncConfig(run_async=False),
):
my_ai_agent(golden.input)See tracing for the full @observe and update_current_trace surface.
Build your agent with create_agent, then pass deepeval's CallbackHandler to its invoke / ainvoke method inside the loop:
import asyncio
from langchain.agents import create_agent
from deepeval.integrations.langchain import CallbackHandler
from deepeval.metrics import TaskCompletionMetric
...
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
agent = create_agent(
model="openai:gpt-4o-mini",
tools=[multiply],
system_prompt="Be concise.",
)
async def run_agent(prompt: str):
return await agent.ainvoke(
{"messages": [{"role": "user", "content": prompt}]},
config={"callbacks": [CallbackHandler()]},
)
for golden in dataset.evals_iterator(metrics=[TaskCompletionMetric()]):
task = asyncio.create_task(run_agent(golden.input))
dataset.evaluate(task)from langchain.agents import create_agent
from deepeval.evaluate import AsyncConfig
from deepeval.integrations.langchain import CallbackHandler
from deepeval.metrics import TaskCompletionMetric
...
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
agent = create_agent(
model="openai:gpt-4o-mini",
tools=[multiply],
system_prompt="Be concise.",
)
for golden in dataset.evals_iterator(
metrics=[TaskCompletionMetric()],
async_config=AsyncConfig(run_async=False),
):
agent.invoke(
{"messages": [{"role": "user", "content": golden.input}]},
config={"callbacks": [CallbackHandler()]},
)See the LangChain integration for the full surface.
Wire your StateGraph, then pass deepeval's CallbackHandler to its invoke / ainvoke method inside the loop:
import asyncio
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START, END
from deepeval.integrations.langchain import CallbackHandler
from deepeval.metrics import TaskCompletionMetric
...
llm = init_chat_model("openai:gpt-4o-mini")
async def chatbot(state: MessagesState):
return {"messages": [await llm.ainvoke(state["messages"])]}
graph = (
StateGraph(MessagesState)
.add_node(chatbot)
.add_edge(START, "chatbot")
.add_edge("chatbot", END)
.compile()
)
async def run_graph(prompt: str):
return await graph.ainvoke(
{"messages": [{"role": "user", "content": prompt}]},
config={"callbacks": [CallbackHandler()]},
)
for golden in dataset.evals_iterator(metrics=[TaskCompletionMetric()]):
task = asyncio.create_task(run_graph(golden.input))
dataset.evaluate(task)from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START, END
from deepeval.evaluate import AsyncConfig
from deepeval.integrations.langchain import CallbackHandler
from deepeval.metrics import TaskCompletionMetric
...
llm = init_chat_model("openai:gpt-4o-mini")
def chatbot(state: MessagesState):
return {"messages": [llm.invoke(state["messages"])]}
graph = (
StateGraph(MessagesState)
.add_node(chatbot)
.add_edge(START, "chatbot")
.add_edge("chatbot", END)
.compile()
)
for golden in dataset.evals_iterator(
metrics=[TaskCompletionMetric()],
async_config=AsyncConfig(run_async=False),
):
graph.invoke(
{"messages": [{"role": "user", "content": golden.input}]},
config={"callbacks": [CallbackHandler()]},
)See the LangGraph integration for the full surface.
Drop-in replace from openai import OpenAI with from deepeval.openai import OpenAI (or AsyncOpenAI). Wrap the call in with trace(): so the LLM call becomes a trace:
import asyncio
from deepeval.openai import AsyncOpenAI
from deepeval.tracing import trace
from deepeval.metrics import TaskCompletionMetric
...
client = AsyncOpenAI()
async def call_openai(prompt: str):
with trace():
return await client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
)
for golden in dataset.evals_iterator(metrics=[TaskCompletionMetric()]):
task = asyncio.create_task(call_openai(golden.input))
dataset.evaluate(task)from deepeval.openai import OpenAI
from deepeval.tracing import trace
from deepeval.evaluate import AsyncConfig
from deepeval.metrics import TaskCompletionMetric
...
client = OpenAI()
for golden in dataset.evals_iterator(
metrics=[TaskCompletionMetric()],
async_config=AsyncConfig(run_async=False),
):
with trace():
client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": golden.input}],
)See the OpenAI integration for streaming and tool-calling.
Pass DeepEvalInstrumentationSettings() to your Agent's instrument keyword:
import asyncio
from pydantic_ai import Agent
from deepeval.integrations.pydantic_ai import DeepEvalInstrumentationSettings
from deepeval.metrics import TaskCompletionMetric
...
agent = Agent(
"openai:gpt-4.1",
system_prompt="Be concise.",
instrument=DeepEvalInstrumentationSettings(),
)
for golden in dataset.evals_iterator(metrics=[TaskCompletionMetric()]):
task = asyncio.create_task(agent.run(golden.input))
dataset.evaluate(task)from pydantic_ai import Agent
from deepeval.evaluate import AsyncConfig
from deepeval.integrations.pydantic_ai import DeepEvalInstrumentationSettings
from deepeval.metrics import TaskCompletionMetric
...
agent = Agent(
"openai:gpt-4.1",
system_prompt="Be concise.",
instrument=DeepEvalInstrumentationSettings(),
)
for golden in dataset.evals_iterator(
metrics=[TaskCompletionMetric()],
async_config=AsyncConfig(run_async=False),
):
agent.run_sync(golden.input)See the Pydantic AI integration for the full surface.
Call instrument_agentcore() before creating your agent. The same call also instruments Strands agents running inside AgentCore:
import asyncio
from strands import Agent
from deepeval.integrations.agentcore import instrument_agentcore
from deepeval.metrics import TaskCompletionMetric
...
instrument_agentcore()
agent = Agent(model="amazon.nova-lite-v1:0")
for golden in dataset.evals_iterator(metrics=[TaskCompletionMetric()]):
task = asyncio.create_task(agent.invoke_async(golden.input))
dataset.evaluate(task)from strands import Agent
from deepeval.evaluate import AsyncConfig
from deepeval.integrations.agentcore import instrument_agentcore
from deepeval.metrics import TaskCompletionMetric
...
instrument_agentcore()
agent = Agent(model="amazon.nova-lite-v1:0")
for golden in dataset.evals_iterator(
metrics=[TaskCompletionMetric()],
async_config=AsyncConfig(run_async=False),
):
agent(golden.input)See the AgentCore integration for the full surface (including the BedrockAgentCoreApp entrypoint pattern).
Call instrument_strands() before invoking your Strands agent (for AgentCore-hosted Strands, use the AgentCore tab instead):
import asyncio
from strands import Agent
from strands.models.openai import OpenAIModel
from deepeval.integrations.strands import instrument_strands
from deepeval.metrics import TaskCompletionMetric
...
instrument_strands()
agent = Agent(
model=OpenAIModel(model_id="gpt-4o-mini"),
system_prompt="You are a helpful assistant.",
)
for golden in dataset.evals_iterator(metrics=[TaskCompletionMetric()]):
task = asyncio.create_task(agent.invoke_async(golden.input))
dataset.evaluate(task)from strands import Agent
from strands.models.openai import OpenAIModel
from deepeval.evaluate import AsyncConfig
from deepeval.integrations.strands import instrument_strands
from deepeval.metrics import TaskCompletionMetric
...
instrument_strands()
agent = Agent(
model=OpenAIModel(model_id="gpt-4o-mini"),
system_prompt="You are a helpful assistant.",
)
for golden in dataset.evals_iterator(
metrics=[TaskCompletionMetric()],
async_config=AsyncConfig(run_async=False),
):
agent(golden.input)See the Strands integration for the full surface.
Drop-in replace from anthropic import Anthropic with from deepeval.anthropic import Anthropic (or AsyncAnthropic). Wrap the call in with trace(): so the LLM call becomes a trace:
import asyncio
from deepeval.anthropic import AsyncAnthropic
from deepeval.tracing import trace
from deepeval.metrics import TaskCompletionMetric
...
client = AsyncAnthropic()
async def call_claude(prompt: str):
with trace():
return await client.messages.create(
model="claude-sonnet-4-5",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}],
)
for golden in dataset.evals_iterator(metrics=[TaskCompletionMetric()]):
task = asyncio.create_task(call_claude(golden.input))
dataset.evaluate(task)from deepeval.anthropic import Anthropic
from deepeval.tracing import trace
from deepeval.evaluate import AsyncConfig
from deepeval.metrics import TaskCompletionMetric
...
client = Anthropic()
for golden in dataset.evals_iterator(
metrics=[TaskCompletionMetric()],
async_config=AsyncConfig(run_async=False),
):
with trace():
client.messages.create(
model="claude-sonnet-4-5",
max_tokens=1024,
messages=[{"role": "user", "content": golden.input}],
)See the Anthropic integration for streaming and tool-use.
Register deepeval's event handler against LlamaIndex's instrumentation dispatcher. agent.run(...) is async-only, so the sync variant uses asyncio.run(...):
import asyncio
from llama_index.llms.openai import OpenAI
from llama_index.core.agent import FunctionAgent
import llama_index.core.instrumentation as instrument
from deepeval.integrations.llama_index import instrument_llama_index
from deepeval.metrics import TaskCompletionMetric
...
instrument_llama_index(instrument.get_dispatcher())
def multiply(a: float, b: float) -> float:
return a * b
agent = FunctionAgent(
tools=[multiply],
llm=OpenAI(model="gpt-4o-mini"),
system_prompt="You are a helpful calculator.",
)
for golden in dataset.evals_iterator(metrics=[TaskCompletionMetric()]):
task = asyncio.create_task(agent.run(golden.input))
dataset.evaluate(task)import asyncio
from llama_index.llms.openai import OpenAI
from llama_index.core.agent import FunctionAgent
import llama_index.core.instrumentation as instrument
from deepeval.evaluate import AsyncConfig
from deepeval.integrations.llama_index import instrument_llama_index
from deepeval.metrics import TaskCompletionMetric
...
instrument_llama_index(instrument.get_dispatcher())
def multiply(a: float, b: float) -> float:
return a * b
agent = FunctionAgent(
tools=[multiply],
llm=OpenAI(model="gpt-4o-mini"),
system_prompt="You are a helpful calculator.",
)
for golden in dataset.evals_iterator(
metrics=[TaskCompletionMetric()],
async_config=AsyncConfig(run_async=False),
):
asyncio.run(agent.run(golden.input))See the LlamaIndex integration for the full surface.
Register DeepEvalTracingProcessor once, then build your agent with deepeval's Agent and function_tool shims:
import asyncio
from agents import Runner, add_trace_processor
from deepeval.openai_agents import Agent, DeepEvalTracingProcessor, function_tool
from deepeval.metrics import TaskCompletionMetric
...
add_trace_processor(DeepEvalTracingProcessor())
@function_tool
def get_weather(city: str) -> str:
return f"It's always sunny in {city}!"
agent = Agent(
name="weather_agent",
instructions="Answer weather questions concisely.",
tools=[get_weather],
)
for golden in dataset.evals_iterator(metrics=[TaskCompletionMetric()]):
task = asyncio.create_task(Runner.run(agent, golden.input))
dataset.evaluate(task)from agents import Runner, add_trace_processor
from deepeval.evaluate import AsyncConfig
from deepeval.openai_agents import Agent, DeepEvalTracingProcessor, function_tool
from deepeval.metrics import TaskCompletionMetric
...
add_trace_processor(DeepEvalTracingProcessor())
@function_tool
def get_weather(city: str) -> str:
return f"It's always sunny in {city}!"
agent = Agent(
name="weather_agent",
instructions="Answer weather questions concisely.",
tools=[get_weather],
)
for golden in dataset.evals_iterator(
metrics=[TaskCompletionMetric()],
async_config=AsyncConfig(run_async=False),
):
Runner.run_sync(agent, golden.input)See the OpenAI Agents integration for the full surface.
Call instrument_google_adk() once before building your LlmAgent. ADK's runner.run_async(...) is async-only, so the sync variant uses asyncio.run(...):
import asyncio
from google.adk.agents import LlmAgent
from google.adk.runners import InMemoryRunner
from google.genai import types
from deepeval.integrations.google_adk import instrument_google_adk
from deepeval.metrics import TaskCompletionMetric
...
instrument_google_adk()
agent = LlmAgent(model="gemini-2.0-flash", name="assistant", instruction="Be concise.")
runner = InMemoryRunner(agent=agent, app_name="deepeval-quickstart")
async def run_agent(prompt: str) -> str:
session = await runner.session_service.create_session(
app_name="deepeval-quickstart", user_id="demo-user",
)
message = types.Content(role="user", parts=[types.Part(text=prompt)])
async for event in runner.run_async(
user_id="demo-user", session_id=session.id, new_message=message,
):
if event.is_final_response() and event.content:
return "".join(part.text for part in event.content.parts if getattr(part, "text", None))
return ""
for golden in dataset.evals_iterator(metrics=[TaskCompletionMetric()]):
task = asyncio.create_task(run_agent(golden.input))
dataset.evaluate(task)import asyncio
from google.adk.agents import LlmAgent
from google.adk.runners import InMemoryRunner
from google.genai import types
from deepeval.evaluate import AsyncConfig
from deepeval.integrations.google_adk import instrument_google_adk
from deepeval.metrics import TaskCompletionMetric
...
instrument_google_adk()
agent = LlmAgent(model="gemini-2.0-flash", name="assistant", instruction="Be concise.")
runner = InMemoryRunner(agent=agent, app_name="deepeval-quickstart")
async def run_agent(prompt: str) -> str:
session = await runner.session_service.create_session(
app_name="deepeval-quickstart", user_id="demo-user",
)
message = types.Content(role="user", parts=[types.Part(text=prompt)])
async for event in runner.run_async(
user_id="demo-user", session_id=session.id, new_message=message,
):
if event.is_final_response() and event.content:
return "".join(part.text for part in event.content.parts if getattr(part, "text", None))
return ""
for golden in dataset.evals_iterator(
metrics=[TaskCompletionMetric()],
async_config=AsyncConfig(run_async=False),
):
asyncio.run(run_agent(golden.input))See the Google ADK integration for the full surface.
Call instrument_crewai() once, then build your crew with deepeval's Crew, Agent, and @tool shims:
import asyncio
from crewai import Task
from deepeval.integrations.crewai import instrument_crewai, Crew, Agent
from deepeval.metrics import TaskCompletionMetric
...
instrument_crewai()
tutor = Agent(
role="Math Tutor",
goal="Answer math questions accurately and concisely.",
backstory="An experienced tutor who explains simple math clearly.",
)
answer_task = Task(
description="{question}",
expected_output="An accurate, concise answer.",
agent=tutor,
)
crew = Crew(agents=[tutor], tasks=[answer_task])
for golden in dataset.evals_iterator(metrics=[TaskCompletionMetric()]):
task = asyncio.create_task(crew.kickoff_async({"question": golden.input}))
dataset.evaluate(task)from crewai import Task
from deepeval.evaluate import AsyncConfig
from deepeval.integrations.crewai import instrument_crewai, Crew, Agent
from deepeval.metrics import TaskCompletionMetric
...
instrument_crewai()
tutor = Agent(
role="Math Tutor",
goal="Answer math questions accurately and concisely.",
backstory="An experienced tutor who explains simple math clearly.",
)
task = Task(
description="{question}",
expected_output="An accurate, concise answer.",
agent=tutor,
)
crew = Crew(agents=[tutor], tasks=[task])
for golden in dataset.evals_iterator(
metrics=[TaskCompletionMetric()],
async_config=AsyncConfig(run_async=False),
):
crew.kickoff({"question": golden.input})See the CrewAI integration for the full surface.
✅ Done. The metrics you pass to evals_iterator() score each trace end-to-end; for its five other optional arguments, see the single-turn end-to-end guide.
Like deepeval test run, every evals_iterator() run is saved locally — view the full execution trace in the same trace-tree TUI:
deepeval inspectEvaluate Sub-Agents
In multi-agent systems, every sub-agent invocation — a delegation, handoff, or nested call — emits its own agent span inside the trace. To evaluate a sub-agent in isolation, attach metrics to its agent span instead of the trace.
Mark your sub-agent with @observe(type="agent") and pass metrics=[...] to it:
from deepeval.tracing import observe, update_current_trace
from deepeval.metrics import TaskCompletionMetric
...
@observe()
def supervisor_agent(query: str) -> str:
research = research_agent(query)
answer = "..." # synthesize final answer here
update_current_trace(input=query, output=answer)
return answer
@observe(type="agent", metrics=[TaskCompletionMetric()])
def research_agent(query: str) -> str:
return "..." # your sub-agent implementationStage a metric for the next agent span with next_agent_span(...) — the CallbackHandler drains it onto the next agent span opened during the run:
from deepeval.tracing import next_agent_span
from deepeval.integrations.langchain import CallbackHandler
from deepeval.metrics import TaskCompletionMetric
...
def run_agent(prompt: str):
with next_agent_span(metrics=[TaskCompletionMetric()]):
return agent.invoke(
{"messages": [{"role": "user", "content": prompt}]},
config={"callbacks": [CallbackHandler()]},
)Like next_llm_span, this is one-shot — only the first agent span in the run picks up the metric.
Stage a metric for the next agent span with next_agent_span(...) — the CallbackHandler drains it onto the next agent span opened during the graph run (e.g. a sub-agent node or subgraph):
from deepeval.tracing import next_agent_span
from deepeval.integrations.langchain import CallbackHandler
from deepeval.metrics import TaskCompletionMetric
...
def run_graph(prompt: str):
with next_agent_span(metrics=[TaskCompletionMetric()]):
return graph.invoke(
{"messages": [{"role": "user", "content": prompt}]},
config={"callbacks": [CallbackHandler()]},
)Like next_llm_span, this is one-shot — only the first agent span in the graph run picks up the metric.
Stage a metric for the next agent span with next_agent_span(...) — delegations and handoffs nest as their own agent spans:
from deepeval.tracing import next_agent_span
from deepeval.metrics import TaskCompletionMetric
...
async def run_agent(prompt: str):
with next_agent_span(metrics=[TaskCompletionMetric()]):
return await agent.run(prompt)Stage a metric for the next agent span with next_agent_span(...):
from deepeval.tracing import next_agent_span
from deepeval.metrics import TaskCompletionMetric
...
def run_agent(prompt: str):
with next_agent_span(metrics=[TaskCompletionMetric()]):
return invoke({"prompt": prompt})Stage a metric for the next agent span with next_agent_span(...):
from deepeval.metrics import TaskCompletionMetric
from deepeval.tracing import next_agent_span
...
def run_agent(prompt: str):
with next_agent_span(metrics=[TaskCompletionMetric()]):
return agent(prompt)Stage a metric for the agent span with AgentSpanContext(metrics=[...]) inside with trace(...):
from deepeval.tracing import trace, AgentSpanContext
from deepeval.metrics import TaskCompletionMetric
...
async def run_agent(prompt: str):
with trace(agent_span_context=AgentSpanContext(metrics=[TaskCompletionMetric()])):
return await agent.run(prompt)Attach agent_metrics=[...] to the sub-agent's Agent shim — it scores that agent's span on every run, including when it's reached through a handoff:
from deepeval.openai_agents import Agent
from deepeval.metrics import TaskCompletionMetric, AnswerRelevancyMetric
...
triage_agent = Agent(
name="triage",
instructions="Route the question to the right specialist.",
handoffs=[
Agent(
name="weather_specialist",
instructions="Answer weather questions.",
tools=[get_weather],
agent_metrics=[TaskCompletionMetric()],
),
],
agent_metrics=[AnswerRelevancyMetric()],
)Stage a metric for the next agent span with next_agent_span(...):
from deepeval.tracing import next_agent_span
from deepeval.metrics import TaskCompletionMetric
...
async def run_agent_with_metric(prompt: str):
with next_agent_span(metrics=[TaskCompletionMetric()]):
return await run_agent(prompt)Attach metrics=[...] to the specific Agent shim — it scores that agent's span on every execution, independent of the rest of the crew:
from deepeval.integrations.crewai import Agent
from deepeval.metrics import TaskCompletionMetric
...
reporter = Agent(
role="Weather Reporter",
goal="Provide accurate weather information.",
backstory="An experienced meteorologist.",
tools=[get_weather],
metrics=[TaskCompletionMetric()],
)Then run your evals exactly as before — evals_iterator() in scripts, or assert_test(golden=golden) in CI/CD. Trace-level metrics are optional here since the metrics already live on the sub-agent spans.
Next Steps
Now that you have run your first agentic evals, you should:
- Customize your metrics: Update the list of metrics for each component.
- Customize tracing: It helps benchmark and identify different components on the UI.
- Explore the integration docs: Each framework integration has its own page with end-to-end and component-level patterns.
You'll be able to analyze performance over time on traces (end-to-end) and spans (component-level).
Evals on traces are end-to-end evaluations, where a single LLM interaction is being evaluated.
Spans make up a trace and evals on spans represents component-level evaluations, where individual components in your LLM app are being evaluated.