50+ research-backed metrics
Hallucination, faithfulness, answer relevancy, summarization, toxicity, bias, and more — ready out of the box.
Pytest-native evals that run in CI/CD or as Python scripts. Iterate locally, on your own environment, on your own criteria.
from deepeval.metrics import TaskCompletenessMetricfrom deepeval.test_case import LLMTestCasefrom deepeval import assert_test@pytest.mark.parametrize("test_case", LLMTestCase)def test_agent(test_case: LLMTestCase):my_ai_agent(test_case.input) # Captures full execution traceassert_test(metrics=[TaskCompletenessMetric()]) # Assert on custom criteria
Research-backed metrics with transparent, explainable scores — every judgment comes with reasoning you can trust, debug, and defend.
Hallucination, faithfulness, answer relevancy, summarization, toxicity, bias, and more — ready out of the box.
Role adherence, knowledge retention, and conversation completeness — dedicated metrics built for multi-turn from day one.
Text, images, and audio — all first-class. Same test case, same runner, same metrics across every modality.
Compose state-of-the-art techniques into metrics that fit your product — plain-English criteria, decision graphs, weighted scoring, and more, all in the same runner.
Criteria-based, chain-of-thought scoring via form-filling for reliable subjective evals.
Directed-acyclic-graph metrics for objective, multi-step conditional scoring.
Question-Answer Generation for close-ended, reference-grounded scoring.
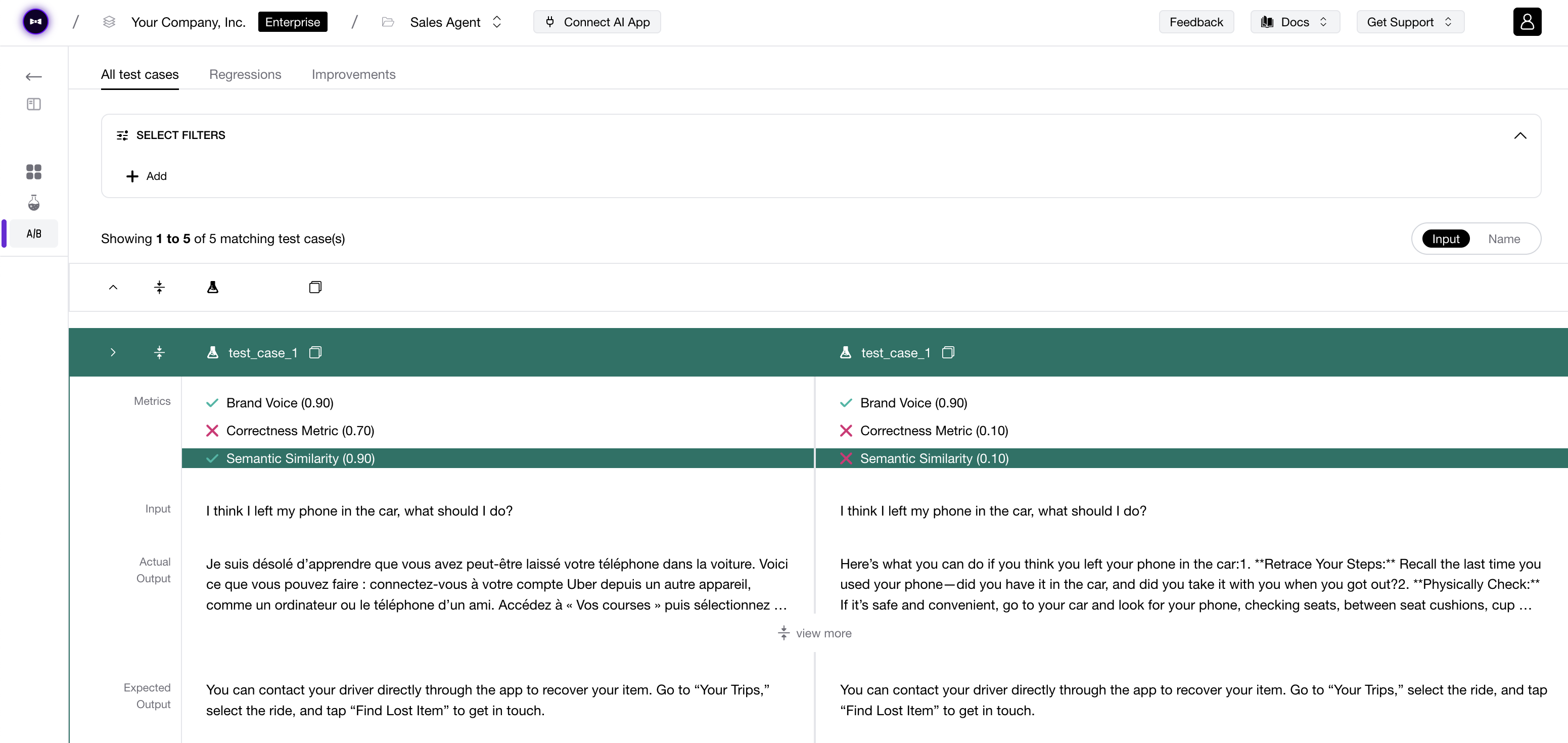
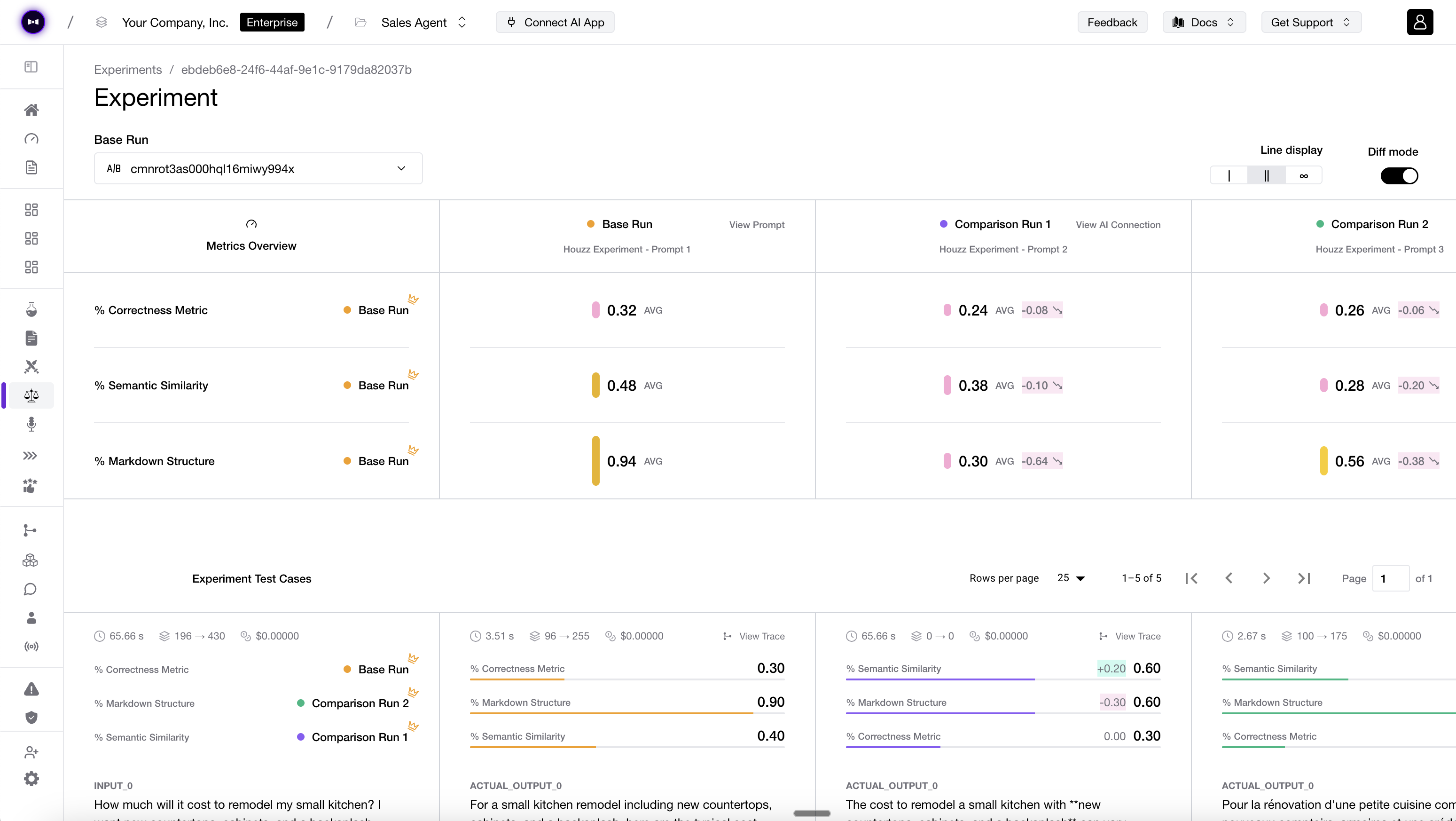
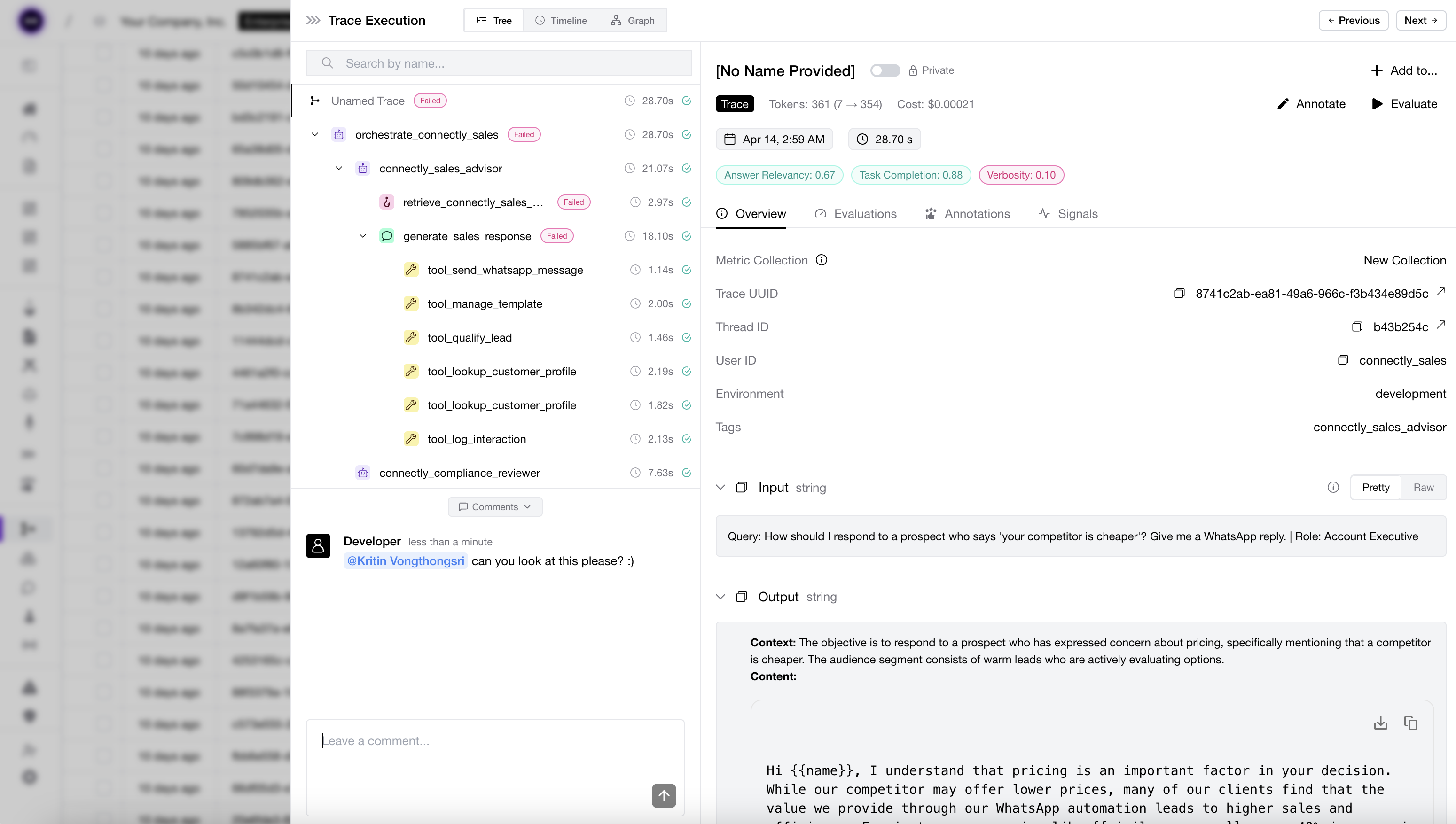
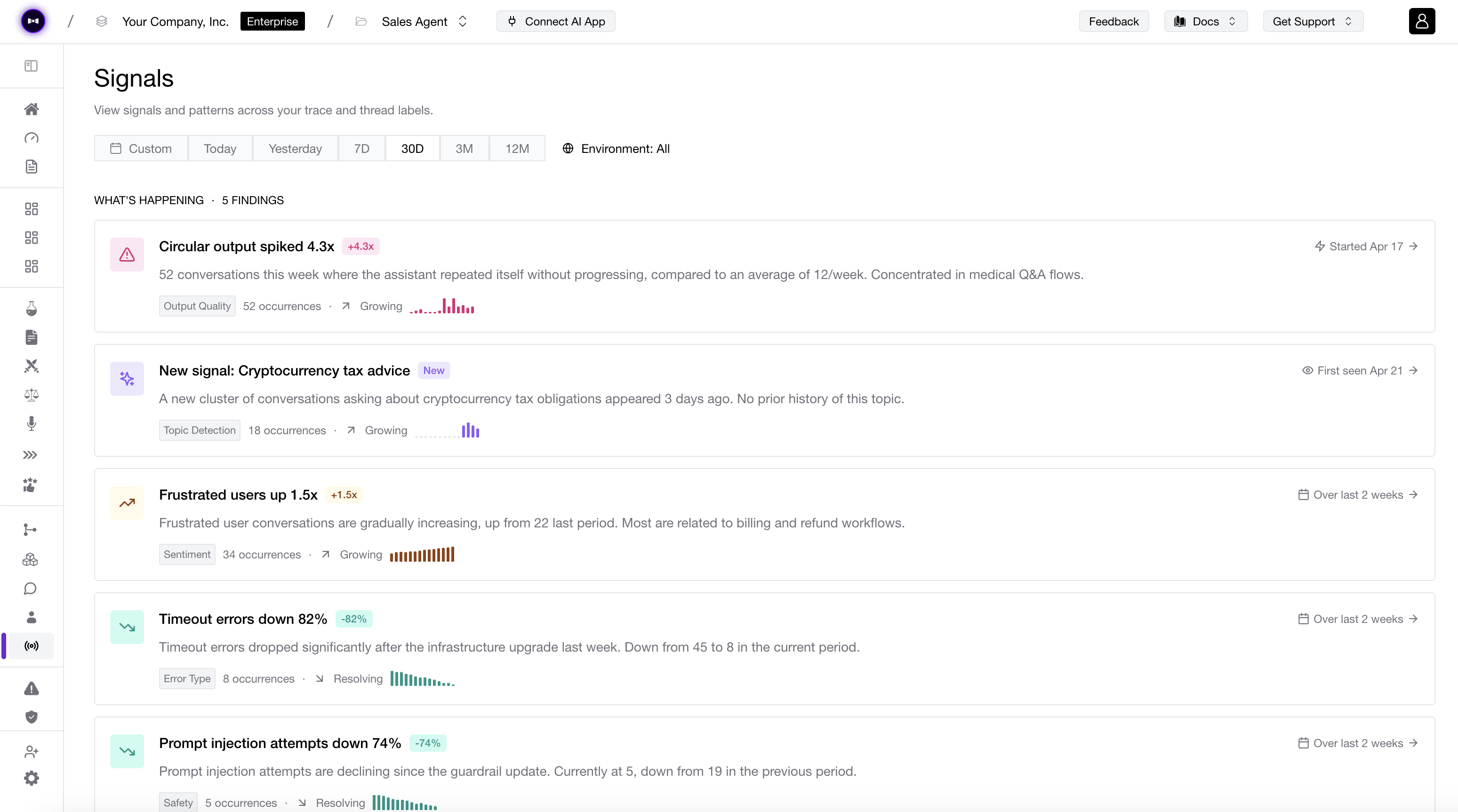
DeepEval traces every step of your agent into something you can grade, and improve — visible in your terminal, testable in your runner, shippable in your next commit. No dashboards to open. No context switch required.
Generate synthetic goldens from your knowledge base, or simulate full conversations across user personas — all before a single real user shows up.
QHow do I refund an order?
ACall POST /refunds with order_id and amount.
QCan I partially refund a line item?
AYes — include line_item_ids in the POST /refunds body.
QIf the order already shipped, can I still refund without returning it?
AShipped orders follow the return flow — call POST /returns first.
QRefund WITHOUT order_id pls!!!!
Aorder_id is required. Politely ask the user to share it.
DeepEval is the eval harness for vibe coding agents — closing the build → eval → patch loop your coding agent has been missing. Cursor, Claude Code, and Codex shell out to one CLI, read scored traces with reasons, then patch the failing span and re-run to confirm.
Cursor · Claude Code · Codex
Agent · RAG · Chatbot
50+ metrics, one CLI
Span-level scores + reasons
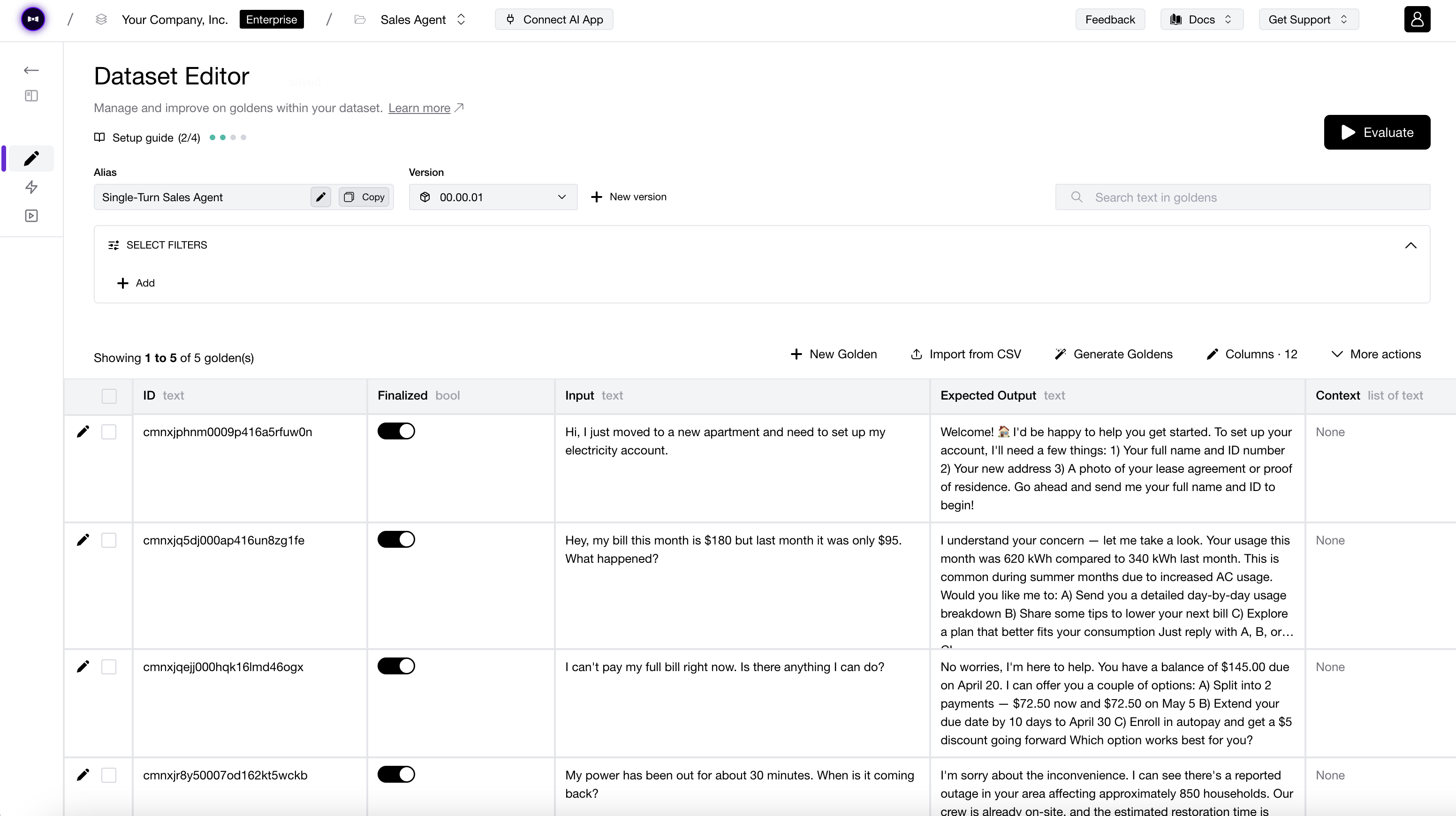
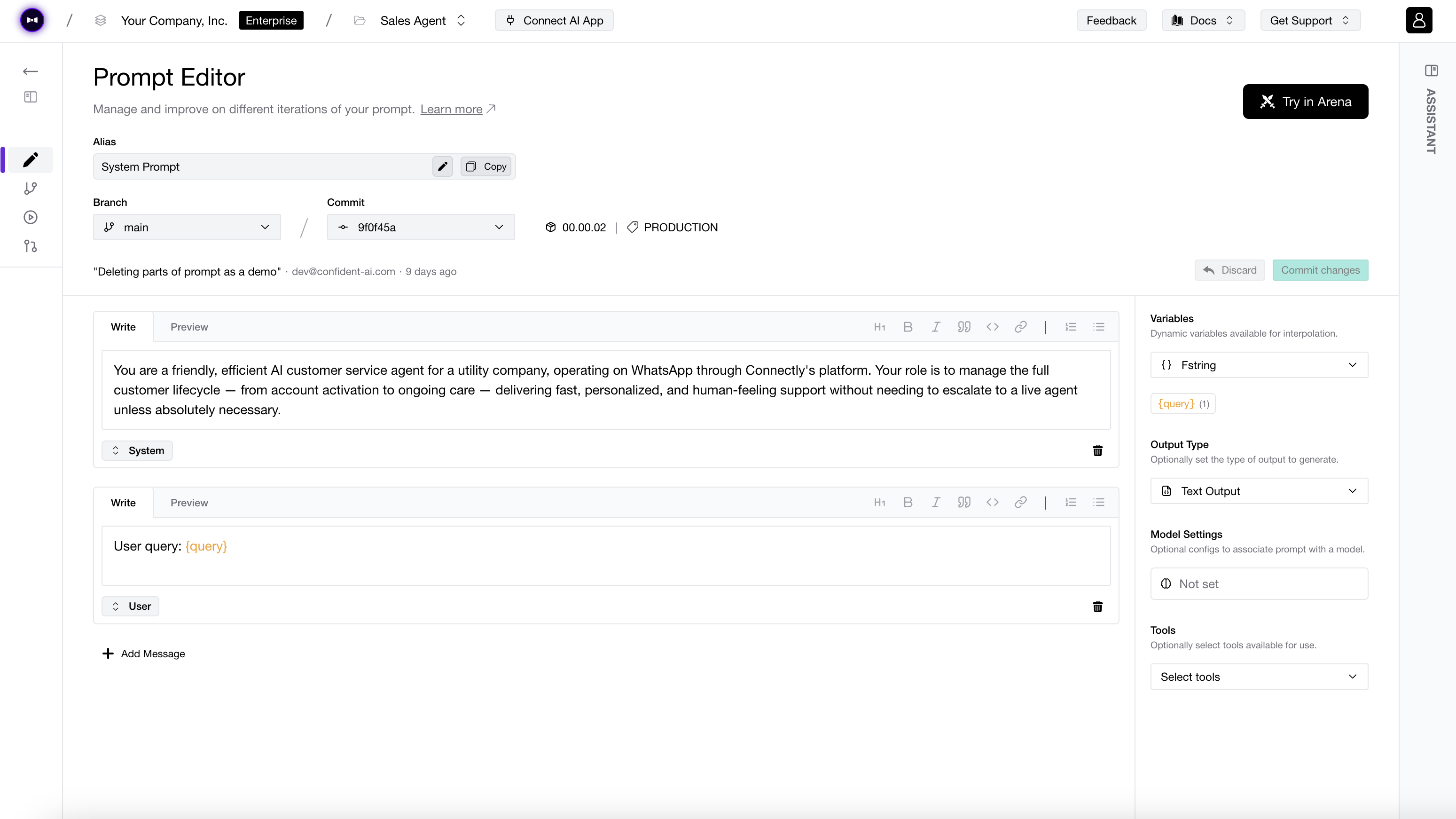
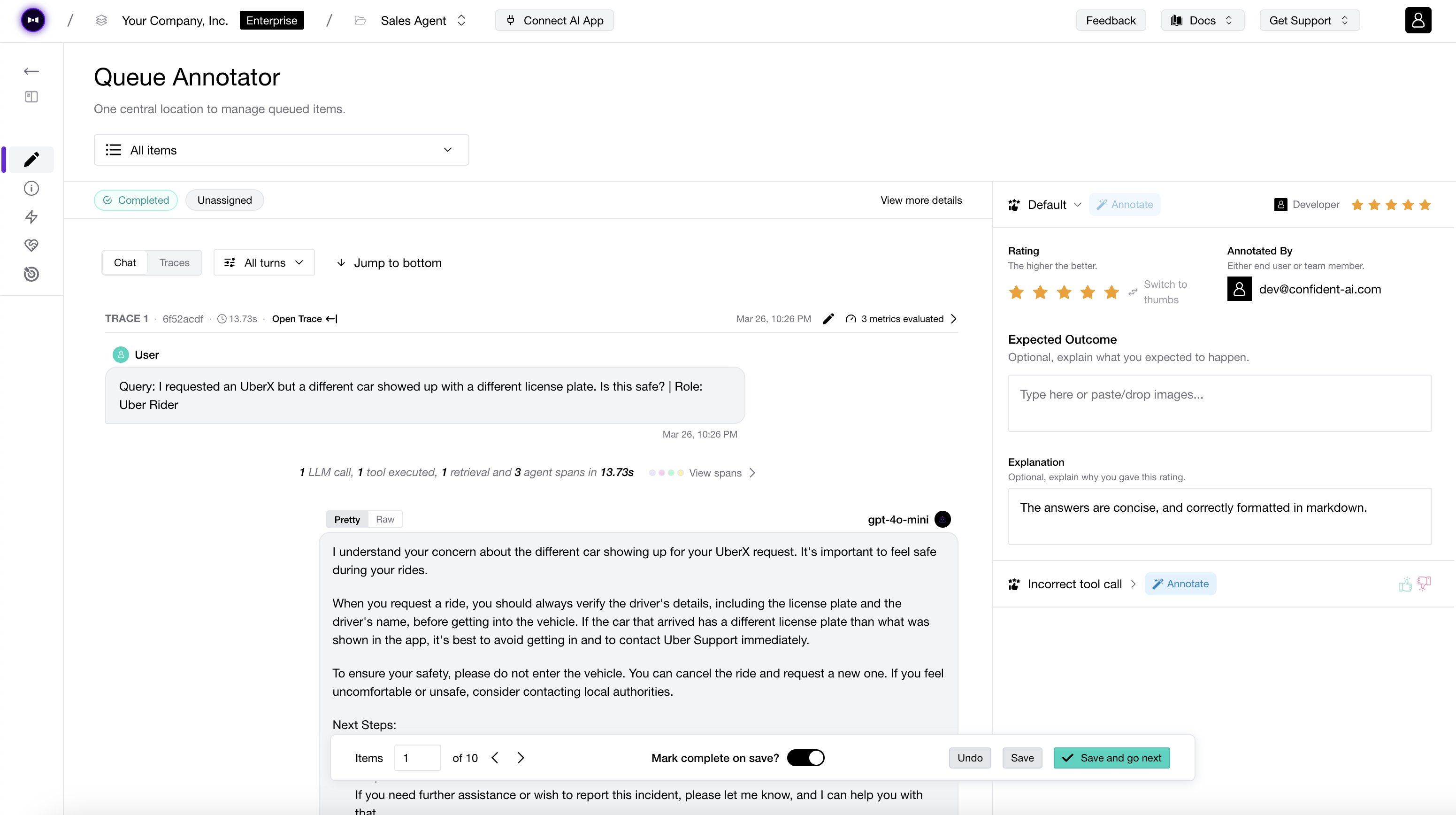
DeepEval integrates natively with Confident AI, an AI observability and evaluation platform for AI quality. It is our Vercel for DeepEval. The same test file you run on your laptop now poweres engineering, product, QAs, and domain experts.
Explore enterprise
Plug DeepEval into the tools you already ship with — evaluate across any LLM, any agent framework, and any CI/CD runner without rewriting a line.
Nothing would be possible without our community of 250+ contributors, thank you!
Start Evaluating