Datasets
In deepeval, an evaluation dataset, or just dataset, is a collection of goldens. A golden is a precursor to a test case. At evaluation time, you would first convert all goldens in your dataset to test cases, before running evals on these test cases.
Quick Summary
There are two approaches to running evals using datasets in deepeval:
- Using
deepeval test run - Using
evaluate
Depending on the type of goldens you supply, datasets are either single-turn or mult-turn. Evaluating a dataset means exactly the same as evaluating your LLM system, because by definition a dataset contains all the information produced by your LLM needed for evaluation.
What are the best practices for curating an evaluation dataset?
- Ensure telling test coverage: Include diverse real-world inputs, varying complexity levels, and edge cases to properly challenge the LLM.
- Focused, quantitative test cases: Design with clear scope that enables meaningful performance metrics without being too broad or narrow.
- Define clear objectives: Align datasets with specific evaluation goals while avoiding unnecessary fragmentation.
Create A Dataset
An EvaluationDataset in deepeval is simply a collection of goldens. You can initialize an empty dataset to start with:
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()A dataset can either be a single-turn one, or a multi-turn one (but not both). During initialization supplying your dataset with a list of Goldens will make it a single-turn one, whereas supplying it with ConversationalGoldens will make it multi-turn:
from deepeval.dataset import EvaluationDataset, Golden
dataset = EvaluationDataset(goldens=[Golden(input="What is your name?")])
print(dataset._multi_turn) # prints Falsefrom deepeval.dataset import EvaluationDataset, ConversationalGolden
dataset = EvaluationDataset(
goldens=[
ConversationalGolden(
scenario="Frustrated user asking for a refund.",
expected_outcome="Redirected to a human agent."
)
]
)
print(dataset._multi_turn) # prints TrueTo ensure best practices, datasets in deepeval are stateful and opinionated. This means you cannot change the value of _multi_turn once its value has been set. However, you can always add new goldens after initialization using the add_golden method:
...
dataset.add_golden(Golden(input="Nice."))...
dataset.add_golden(
ConversationalGolden(
scenario="User expressing gratitude for redirecting to human.",
expected_outcome="Appreciates the gratitude."
)
)Run Evals On Dataset
You run evals on test cases in datasets, which you'll create at evaluation time using the goldens in the same dataset.
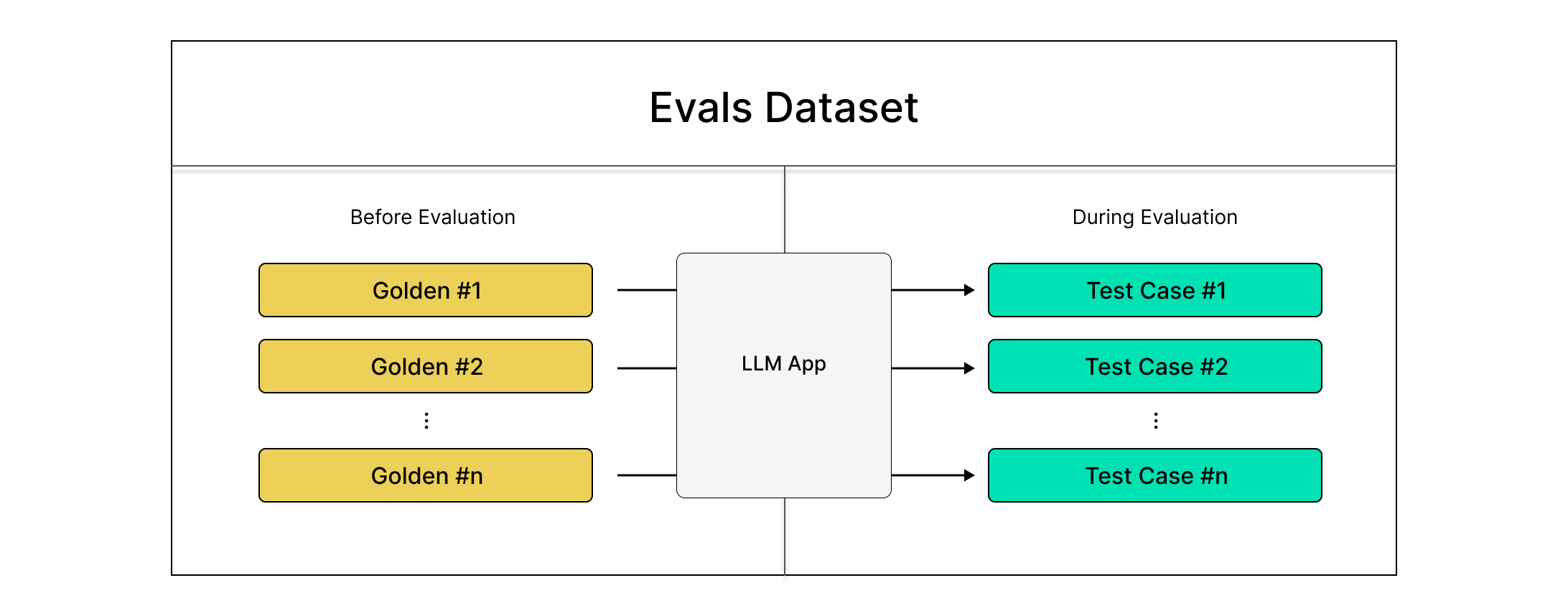
First step is to load in the goldens to your dataset. This example will load datasets from Confident AI, but you can also explore other options below.
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.pull(alias="My Dataset") # replace with your alias
print(dataset.goldens) # print to sanity check yourselfOnce you have your dataset and can see a non-empty list of goldens, you can start generating outputs and add it back to your dataset as test cases via the add_test_case() method:
from deepeval.test_case import LLMTestCase
...
for golden in dataset.goldens:
test_case = LLMTestCase(
input=golden.input,
actual_output=your_llm_app(golden.input) # replace with your LLM app
)
dataset.add_test_case(test_case)
print(dataset.test_cases) # print to santiy check yourselfLastly, you can run evaluations on the list of test cases in your dataset:
import pytest
from deepeval.metrics import AnswerRelevancyMetric
...
@pytest.mark.parametrize("test_case", dataset.test_cases)
def test_llm_app(test_case: LLMTestCase):
assert_test(test_case=test_case, metrics=[AnswerRelevancyMetric()])And execute the test file:
deepeval test run test_llm_app.pyYou can learn more about assert_test in this section.
from deepeval.metrics import AnswerRelevancyMetric
from deepeval import evaluate
...
evaluate(test_cases=dataset.test_cases, metrics=[AnswerRelevancyMetric()])And run main.py:
python main.pyYou can learn more about evaluate in this section.
from deepeval.test_case import ConversationalTestCase
...
for golden in dataset.goldens:
test_case = ConversationalTestCase(
scenario=golden.scenario,
turns=generate_turns(golden.scenario) # replace with your method to simulate conversations
)
dataset.add_test_case(test_case)
print(dataset.test_cases) # print to santiy check yourselfLastly, you can run evaluations on the list of test cases in your dataset:
import pytest
from deepeval.metrics import ConversationalRelevancyMetric
...
@pytest.mark.parametrize("test_case", dataset.test_cases)
def test_llm_app(test_case: ConversationalTestCase):
assert_test(test_case=test_case, metrics=[ConversationalRelevancyMetric()])And execute the test file:
deepeval test run test_llm_app.pyYou can learn more about assert_test in this section.
from deepeval.metrics import ConversationalRelevancyMetric
from deepeval import evaluate
...
evaluate(test_cases=dataset.test_cases, metrics=[ConversationalRelevancyMetric()])And run main.py:
python main.pyYou can learn more about evaluate in this section.
Manage Your Dataset
Dataset management is an essential part of your evaluation lifecycle. We recommend Confident AI as the choice for your dataset management workflow as it comes with dozens of collaboration features out of the box, but you can also do it locally as well.
Save Dataset
You can store both single-turn and multi-turn datasets with deepeval. The single-turn datasets contains a list of Goldens and the multi-turn would contain ConversationalGoldens instead.
You can save your dataset on the cloud by using the push method:
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset(goldens)
dataset.push(alias="My dataset")This pushes all goldens in your evaluation dataset to Confident AI. If you're unsure whether your goldens are ready for evaluation, you should set finalized to False instead:
...
dataset.push(alias="My dataset", finalized=False)This means they won't be pulled until you've manually marked them as finalized on the platform. You can learn more on Confident AI's docs here.
You can save your dataset locally to a JSON file by using the save_as() method:
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset(goldens)
dataset.save_as(
file_type="json",
directory="./deepeval-test-dataset",
)There are TWO mandatory and TWO optional parameter when calling the save_as() method:
file_type: a string of either"csv"or"json"and specifies which file format to saveGoldens in.directory: a string specifying the path of the directory you wish to saveGoldens at.file_name: a string specifying the custom filename for the dataset file. Defaulted to the "YYYYMMDD_HHMMSS" format of time now.include_test_cases: a boolean which when set toTrue, will also save any test cases within your dataset. Defaulted toFalse.
You can save your dataset locally to a CSV file by using the save_as() method:
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset(goldens)
dataset.save_as(
file_type="csv",
directory="./deepeval-test-dataset",
)There are TWO mandatory and TWO optional parameter when calling the save_as() method:
file_type: a string of either"csv"or"json"and specifies which file format to saveGoldens in.directory: a string specifying the path of the directory you wish to saveGoldens at.file_name: a string specifying the custom filename for the dataset file. Defaulted to the "YYYYMMDD_HHMMSS" format of time now.include_test_cases: a boolean which when set toTrue, will also save any test cases within your dataset. Defaulted toFalse.
Load Dataset
deepeval offers support for loading datasets stored in JSON, JSONL, CSV, and hugging face datasets into an EvaluationDataset as either test cases or goldens.
You can load entire datasets on Confident AI's cloud in one line of code.
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.pull(alias="My Evals Dataset")Non-technical domain experts can create, annotate, and comment on datasets on Confident AI. You can also upload datasets in CSV format, or push synthetic datasets created in deepeval to Confident AI in one line of code.
For more information, visit the Confident AI datasets section.
You can loading an existing EvaluationDataset you might have generated elsewhere by supplying a file_path to your .json file as either test cases or goldens. Your .json file should contain an array of objects (or list of dictionaries).
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
# Add goldens from a JSON file
dataset.add_goldens_from_json_file(
file_path="example.json",
) # file_path is the absolute path to your .json fileIf your JSON file has different keys from deepeval's conventional Golden or ConversationalGolden parameters. You can supply your custom key names in the function parameters.
You can also add single-turn LLMTestCases to your dataset from a JSON file.
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
# Add as test cases
dataset.add_test_cases_from_json_file(
# file_path is the absolute path to you .json file
file_path="example.json",
input_key_name="query",
actual_output_key_name="actual_output",
expected_output_key_name="expected_output",
context_key_name="context",
retrieval_context_key_name="retrieval_context",
)You can load existing Goldens or ConversationalGoldens from a .jsonl file by supplying a file_path. Each line should contain one JSON object that maps to either a Golden or a ConversationalGolden.
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
# Add goldens from a JSONL file
dataset.add_goldens_from_jsonl_file(
file_path="example.jsonl",
) # file_path is the absolute path to your .jsonl fileFor single-turn goldens, each line can look like:
{"input": "What is DeepEval?", "expected_output": "An LLM evaluation framework.", "context": ["DeepEval helps evaluate LLM apps."]}For multi-turn goldens, each line can look like:
{"scenario": "A user asks for help evaluating an LLM app.", "expected_outcome": "The user understands how to create an evaluation dataset.", "context": ["DeepEval supports evaluation datasets."]}You can add test cases or goldens into your EvaluationDataset by supplying a file_path to your .csv file. Your .csv file should contain rows that can be mapped into Golden or ConversationalGolden through their column names.
Remember, parameters such as context should be a list of strings and in the context of CSV files, it means you have to supply a context_col_delimiter argument to tell deepeval how to split your context cells into a list of strings.
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
# Add goldens
dataset.add_goldens_from_csv_file(
file_path="example.csv",
) # file_path is the absolute path to you .csv fileIf your CSV file has different column names from deepeval's conventional Golden or ConversationalGolden parameters. You can supply your custom column names in the function parameters.
You can also add single-turn LLMTestCases to your dataset from a CSV file.
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
# Add as test cases
dataset.add_test_cases_from_csv_file(
# file_path is the absolute path to you .csv file
file_path="example.csv",
input_col_name="query",
actual_output_col_name="actual_output",
expected_output_col_name="expected_output",
context_col_name="context",
context_col_delimiter= ";",
retrieval_context_col_name="retrieval_context",
retrieval_context_col_delimiter= ";"
)Generate A Dataset
Sometimes, you might not have datasets ready to use, and that's ok. deepeval provides two options for both single-turn and multi-turn use cases:
Synthesizerfor generating single-turn goldensConversationSimulatorfor generatingturns in aConversationalTestCase
Synthesizer
deepeval offers anyone the ability to easily generate synthetic datasets from documents locally on your machine. This is especially helpful if you don't have an evaluation dataset prepared beforehand.
from deepeval.synthesizer import Synthesizer
goldens = Synthesizer().generate_goldens_from_docs(
document_paths=['example.txt', 'example.docx', 'example.pdf']
)
dataset = EvaluationDataset(goldens=goldens)In this example, we've used the generate_goldens_from_docs method, which is one of the four generation methods offered by deepeval's Synthesizer. The four methods include:
generate_goldens_from_docs(): useful for generating goldens to evaluate your LLM application based on contexts extracted from your knowledge base in the form of documents.generate_goldens_from_contexts(): useful for generating goldens to evaluate your LLM application based on a list of prepared context.generate_goldens_from_scratch(): useful for generating goldens to evaluate your LLM application without relying on contexts from a knowledge base.generate_goldens_from_goldens(): useful for generating goldens by augmenting a known set of goldens.
deepeval's Synthesizer uses a series of evolution techniques to complicate and make generated goldens more realistic to human prepared data.
Conversation Simulator
While a Synthesizer generates goldens, the ConversationSimulator works slightly different as it generates turns in a ConversationalTestCase instead:
from deepeval.simulator import ConversationSimulator
# Define simulator
simulator = ConversationSimulator(
user_intentions={"Opening a bank account": 1},
user_profile_items=[
"full name",
"current address",
"bank account number",
"date of birth",
"mother's maiden name",
"phone number",
"country code",
],
)
# Define model callback
async def model_callback(input: str, conversation_history: List[Dict[str, str]]) -> str:
return f"I don't know how to answer this: {input}"
# Start simluation
convo_test_cases = simulator.simulate(
model_callback=model_callback,
stopping_criteria="Stop when the user's banking request has been fully resolved.",
)
print(convo_test_cases)You can learn more in the conversation simulator page.
What Are Goldens?
Goldens represent a more flexible alternative to test cases in the deepeval, and is the preferred way to initialize a dataset. Unlike test cases, goldens:
- Only require
input/scenarioto initialize - Store expected results like
expected_output/expected_outcome - Serve as templates before becoming fully-formed test cases
Goldens excel in development workflows where you need to:
- Evaluate changes across different iterations of your LLM application
- Compare performance between model versions
- Test with
inputs that haven't yet been processed by your LLM
Think of goldens as "pending test cases" - they contain all the input data and expected results, but are missing the dynamic elements (actual_output, retrieval_context, tools_called) that will be generated when your LLM processes them.
Data model
The golden data model is nearly identical to their single/multi-turn test case counterparts (aka. LLMTestCase and ConversationalTestCase).
For single-turn Goldens:
from pydantic import BaseModel
class Golden(BaseModel):
input: str
expected_output: Optional[str] = None
context: Optional[List[str]] = None
expected_tools: Optional[List[ToolCall]] = None
# Useful metadata for generating test cases
additional_metadata: Optional[Dict] = None
comments: Optional[str] = None
custom_column_key_values: Optional[Dict[str, str]] = None
# Fields that you should ideally not populate
actual_output: Optional[str] = None
retrieval_context: Optional[List[str]] = None
tools_called: Optional[List[ToolCall]] = NoneFor multi-turn ConversationalGoldens:
from pydantic import BaseModel
class ConversationalGolden(BaseModel):
scenario: str
expected_outcome: Optional[str] = None
user_description: Optional[str] = None
context: Optional[List[str]] = None
# Useful metadata for generating test cases
additional_metadata: Optional[Dict] = None
comments: Optional[str] = None
custom_column_key_values: Optional[Dict[str, str]] = None
# Fields that you should ideally not populate
turns: Optional[Turn] = NoneYou can easily add and edit custom columns on Confident AI.
FAQs
What's the difference between a golden and a test case?
input (or scenario) plus expected results, and acts as a "pending test case." It becomes a full test case once your LLM app generates the dynamic fields like actual_output, retrieval_context, and tools_called at evaluation time.Why initialize a dataset with goldens instead of test cases?
Do I need production data to create a dataset?
Can I load datasets from local files?
Can I add custom columns to a golden?
additional_metadata, comments, and custom_column_key_values for arbitrary metadata you want to carry through evaluation.Can my team store, edit, and version datasets on the cloud with a UI?
deepeval team) lets you store datasets in the cloud, edit goldens and custom columns in a UI, and have non-engineers contribute — then pull the same dataset back into code. It's optional and local datasets behave identically.