CLI Settings
Quick Summary
deepeval provides a CLI for managing common tasks directly from the terminal. You can use it for:
- Logging in/out and viewing test runs
- Running evaluations from test files
- Inspecting saved test runs in a terminal TUI (
deepeval inspect) - Generating synthetic goldens from docs, contexts, scratch, or existing goldens
- Enabling/disabling debug
- Selecting an LLM/embeddings provider (OpenAI, Azure OpenAI, Gemini, Grok, DeepSeek, LiteLLM, local/Ollama)
- Setting/unsetting provider-specific options (model, endpoint, deployment, etc.)
- Listing and updating any deepeval setting (
deepeval settings -l,deepeval settings --set KEY=VALUE) - Saving settings and secrets persistently to
.envfiles
Install & Update
pip install -U deepevalTo review available commands consult the CLI built in help:
deepeval --helpRead & Write Settings
deepeval reads settings from dotenv files in the current working directory (or ENV_DIR_PATH=/path/to/project), without overriding existing process environment variables. Dotenv precedence (lowest → highest) is: .env → .env.<APP_ENV> → .env.local.
deepeval also uses a legacy JSON keystore at .deepeval/.deepeval for non-secret keys. This keystore is treated as a fallback (dotenv/process env take precedence). Secrets are never written to the JSON keystore.
Core Commands
generate
Use deepeval generate to generate synthetic goldens from the terminal with the Golden Synthesizer. The command requires two selectors:
--method: where goldens come from:docs,contexts,scratch, orgoldens--variation: what to generate:single-turnormulti-turn
Generate single-turn goldens from documents:
deepeval generate \
--method docs \
--variation single-turn \
--documents example.txt \
--documents another.pdf \
--output-dir ./synthetic_dataGenerate multi-turn goldens from scratch:
deepeval generate \
--method scratch \
--variation multi-turn \
--num-goldens 25 \
--scenario-context "Users asking support questions" \
--conversational-task "Help users solve product issues" \
--participant-roles "User and assistant"Common options:
| Option | Description |
|---|---|
--method docs|contexts|scratch|goldens | Select the generation method. |
--variation single-turn|multi-turn | Select whether to generate Goldens or ConversationalGoldens. |
--output-dir | Directory where generated goldens are saved. Defaults to ./synthetic_data. |
--file-type json|csv|jsonl | Output file type. Defaults to json. |
--file-name | Optional output filename without extension. |
--model | Model to use for generation. |
--async-mode / --sync-mode | Enable or disable concurrent generation. |
--max-concurrent | Maximum number of concurrent generation tasks. |
--include-expected / --no-include-expected | Generate or skip expected outputs/outcomes. |
--cost-tracking | Print generation cost when supported by the model. |
Method-specific options:
| Method | Required Options | Useful Optional Options |
|---|---|---|
docs | --documents | --max-goldens-per-context, --max-contexts-per-document, --min-contexts-per-document, --chunk-size, --chunk-overlap, --context-quality-threshold, --context-similarity-threshold, --max-retries |
contexts | --contexts-file | --max-goldens-per-context |
scratch | --num-goldens plus styling options | Single-turn: --scenario, --task, --input-format, --expected-output-format. Multi-turn: --scenario-context, --conversational-task, --participant-roles, --scenario-format, --expected-outcome-format |
goldens | --goldens-file | --max-goldens-per-golden |
For a deeper walkthrough, see the Golden Synthesizer docs.
test
Use deepeval test run to run evaluation test files through pytest with the deepeval pytest plugin enabled.
deepeval test --help
deepeval test run --helpRun a single test file:
deepeval test run test_chatbot.pyRun a test directory:
deepeval test run tests/evalsRun a specific test:
deepeval test run test_chatbot.py::test_answer_relevancyUseful options:
| Option | Description |
|---|---|
--verbose, -v | Show verbose pytest output and turn on deepeval verbose mode. |
--exit-on-first-failure, -x | Stop after the first failed test. |
--show-warnings, -w | Show pytest warnings instead of disabling them. |
--identifier, -id | Attach an identifier to the test run. |
--num-processes, -n | Run tests with multiple pytest-xdist processes. |
--repeat, -r | Rerun each test case the specified number of times. |
--use-cache, -c | Use cached evaluation results when --repeat is not set. |
--ignore-errors, -i | Continue when deepeval evaluation errors occur. |
--skip-on-missing-params, -s | Skip test cases with missing metric parameters. |
--display, -d | Control final result display. Defaults to showing all results. |
--mark, -m | Run tests matching a pytest marker expression. |
--official, -o | Mark this test run as the official baseline on Confident AI. |
You can pass additional pytest flags after the deepeval options. For example:
deepeval test run tests/evals \
--mark "not slow" \
--exit-on-first-failure \
-- --tb=shortinspect
Use deepeval inspect to open a saved test run inside a terminal TUI — a trace-tree viewer for metric scores, reasons, inputs/outputs, tool calls, and retriever context, all without leaving the terminal.
The TUI is a trace viewer, so it's only useful for runs produced by evals_iterator() with an instrumented agent (see single-turn end-to-end evals). Each such call writes a rolling snapshot to .deepeval/.latest_run_full.json (gitignored alongside the rest of the hidden cache dir), so the zero-arg form picks up the most recent run automatically:
deepeval inspectYou can also point it at a specific file or folder:
deepeval inspect ./experiments/test_run_20260512_174200.json
deepeval inspect ./experiments # latest test_run_*.json inside
deepeval inspect --folder ./experiments # same, via explicit flagThis allows you to inspect traces and spans locally on your machine:
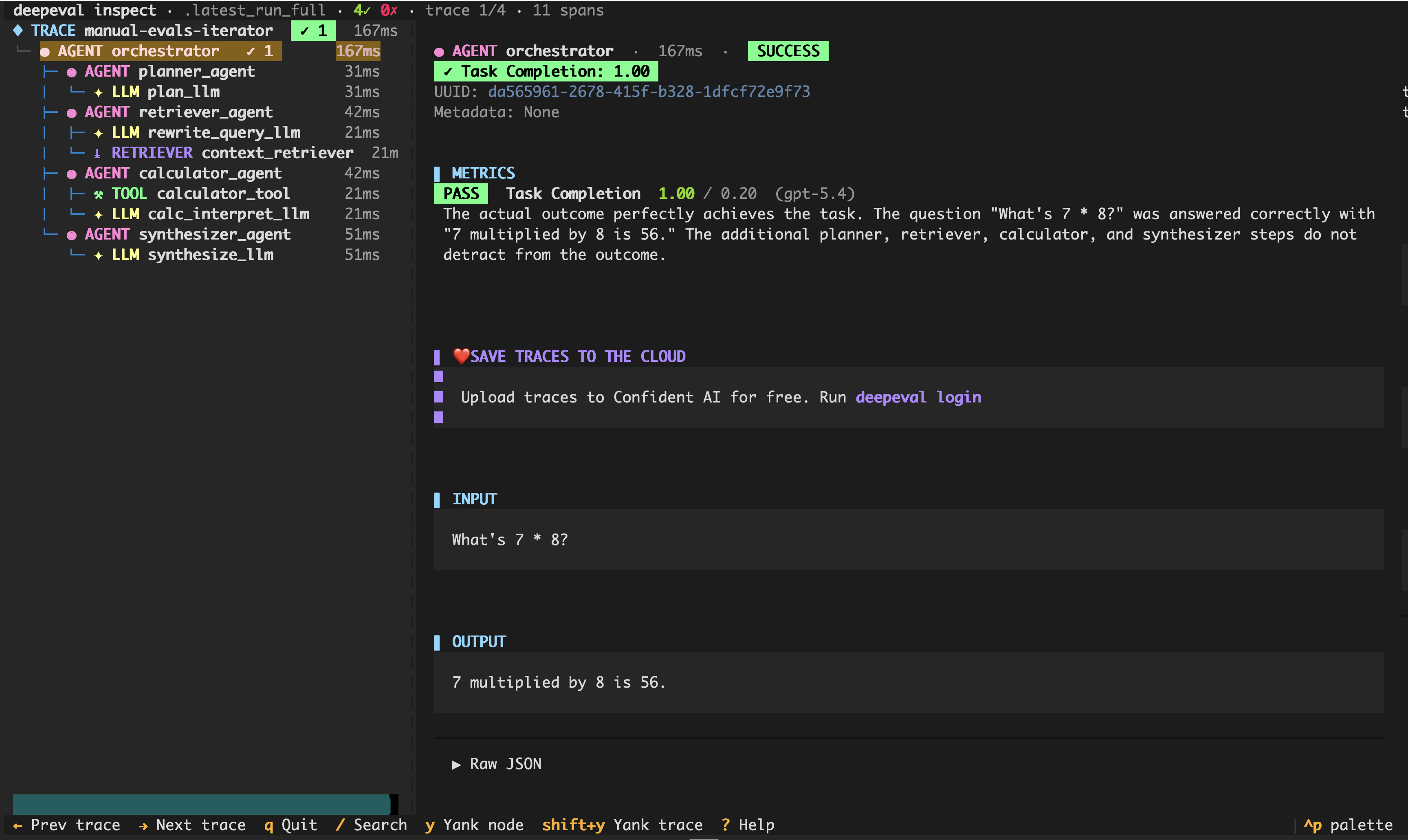
Resolution order when no path is passed: --folder → DEEPEVAL_RESULTS_FOLDER → .deepeval/.latest_run_full.json → ./experiments (legacy fallback).
The TUI needs an optional extras bundle (Textual + clipboard support):
pip install 'deepeval[inspect]'Confident AI Commands
Use these commands to connect deepeval to Confident AI (deepeval Cloud) so your local evaluations can be uploaded, organized, and viewed as rich test run reports on the cloud. If you don’t have an account yet, sign up here.
login & logout
deepeval login [--confident-api-key ...] [--save=dotenv[:path]]: Log in to Confident AI by saving yourCONFIDENT_API_KEY. Once logged in,deepevalcan automatically upload test runs so you can browse results, share reports, and track evaluation performance over time on Confident AI.deepeval logout [--save=dotenv[:path]]: Remove your Confident AI credentials from local persistence (JSON keystore and the chosen dotenv file).
view
deepeval view: Opens the latest test run on Confident AI in your browser. If needed, it uploads the cached run artifacts first.
Persistence & Secrets
All set-* / unset-* commands follow the same rules:
- Non-secrets (model name, endpoint, deployment, etc.) may be mirrored into
.deepeval/.deepeval. - Secrets (API keys) are never written to
.deepeval/.deepeval. - Pass
--save=dotenv[:path]to write settings (including secrets) to a dotenv file (default:.env.local). - If
--saveis omitted, deepeval will useDEEPEVAL_DEFAULT_SAVEif set; otherwise it won’t write a dotenv file (some commands likeloginstill default to.env.local). - Unsetting one provider only removes that provider’s keys. If other provider credentials remain (e.g.
OPENAI_API_KEY), they may still be selected by default.
To set the model and token cost for Anthropic you would run:
deepeval set-anthropic -m claude-3-7-sonnet-latest -i 0.000003 -o 0.000015 --save=dotenv
Saved environment variables to .env.local (ensure it's git-ignored).
🙌 Congratulations! You're now using Anthropic `claude-3-7-sonnet-latest` for all evals that require an LLM.To view your settings for Anthropic you would run:
deepeval settings -l anthropic
Settings
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Name ┃ Value ┃ Description ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ ANTHROPIC_API_KEY │ ******** │ Anthropic API key. │
│ ANTHROPIC_COST_PER_INPUT_TOKEN │ 3e-06 │ Anthropic input token cost (used for cost reporting). │
│ ANTHROPIC_COST_PER_OUTPUT_TOKEN │ 1.5e-05 │ Anthropic output token cost (used for cost reporting). │
│ ANTHROPIC_MODEL_NAME │ claude-3-7-sonnet-latest │ Anthropic model name (e.g. 'claude-3-...'). │
│ USE_ANTHROPIC_MODEL │ True │ Select Anthropic as the active LLM provider (USE_* flags are mutually exclusive in CLI helpers). │
└─────────────────────────────────┴──────────────────────────┴──────────────────────────────────────────────────────────────────────────────────────────────────┘Debug Controls
Use these to turn on structured logs, gRPC wire tracing, and Confident tracing (all optional).
deepeval set-debug \
--log-level DEBUG \
--debug-async \
--retry-before-level INFO \
--retry-after-level ERROR \
--grpc --grpc-verbosity DEBUG --grpc-trace list_tracers \
--trace-verbose --trace-env staging --trace-flush \
--save=dotenv- Immediate effect in the current process
- Optional persistence via
--save=dotenv[:path] - No-op guard: If nothing would change, you’ll see No changes to save … (and nothing is written).
To restore defaults and clean persisted values:
deepeval unset-debug --save=dotenvModel Provider Configs
All provider commands come in pairs:
deepeval set-<provider> [provider-specific flags] [--save=dotenv[:path]] [--quiet]deepeval unset-<provider> [--save=dotenv[:path]] [--quiet]
This switches the active provider:
- It sets
USE_<PROVIDER>_MODEL = Truefor the chosen provider, and - Turns all other
USE_*flags off so that only one provider is enabled at a time.
When you set a provider, the CLI enables that provider’s USE_<PROVIDER>_MODEL flag and disables all other USE_* flags. When you unset a provider, it disables only that provider’s USE_* flag and leaves all others untouched. If you manually set env vars (or edit dotenv files) it’s possible to end up with multiple USE_* flags enabled.
Full model list
| Provider (LLM) | Set | Unset |
|---|---|---|
| OpenAI | set-openai | unset-openai |
| Azure OpenAI | set-azure-openai | unset-azure-openai |
| Anthropic | set-anthropic | unset-anthropic |
| AWS Bedrock | set-bedrock | unset-bedrock |
| Ollama (local) | set-ollama | unset-ollama |
| Local HTTP model | set-local-model | unset-local-model |
| Grok | set-grok | unset-grok |
| Moonshot (Kimi) | set-moonshot | unset-moonshot |
| DeepSeek | set-deepseek | unset-deepseek |
| Gemini | set-gemini | unset-gemini |
| LiteLLM | set-litellm | unset-litellm |
| Portkey | set-portkey | unset-portkey |
Embeddings:
| Provider (Embeddings) | Set | Unset |
|---|---|---|
| Azure OpenAI | set-azure-openai-embedding | unset-azure-openai-embedding |
| Local (HTTP) | set-local-embeddings | unset-local-embeddings |
| Ollama | set-ollama-embeddings | unset-ollama-embeddings |
Common Issues
- Nothing printed? For
set-*/unset-*/set-debug, a clean exit with no output often means you are passing the--quiet/-qflag. - Provider still active after unsetting? Unsetting turns off target provider
USE_*flags; if a provider remains enabled and properly configured it will become the active provider. If no provider is enabled, but OpenAI credentials are present, OpenAI may be used as a fallback. To force a provider, run the correspondingset-<provider>command. - Dotenv edits not picked up? deepeval loads dotenv files from the current working directory by default, or
ENV_DIR_PATHif set. Ensure your Python process runs in that context.
If you’re still stuck, the dedicated Troubleshooting page covers deeper debugging (TLS errors, logging, timeouts, dotenv loading, and config caching).