AI Agent Evaluation
AI agent evaluation is the process of measuring how well an agent reasons, selects and calls tools, and completes tasks—separately at each layer—so you can pinpoint exactly what's broken. But first, what is an AI agent?
An AI agent is an LLM-powered system that autonomously reasons about tasks, creates plans, and executes actions using external tools to accomplish user goals. Unlike simple LLM applications that respond to single prompts, agents operate in loops—reasoning, acting, observing results, and adapting their approach until the task is complete.
Since a successful agent outcome depends entirely on the quality of both reasoning and action, AI agent evaluation focuses on evaluating these layers separately. This allows for easier debugging and to pinpoint issues at the component-level.
Whatever stack you're on, you'll find real, copy-pasteable code examples for 10+ popular agent frameworks below—LangChain, LangGraph, OpenAI Agents, Pydantic AI, CrewAI, Google ADK, and more.
For a comprehensive breakdown of each agentic metric, see the AI Agent Evaluation Metrics guide. To understand where this all fits in the agent stack, read what an eval harness is and why it matters.
Common Pitfalls in AI Agent Pipelines
An AI agent pipeline involves reasoning (planning) and action (tool calling) steps that iterate until task completion. The reasoning layer decides what to do, while the action layer carries out how to do it.
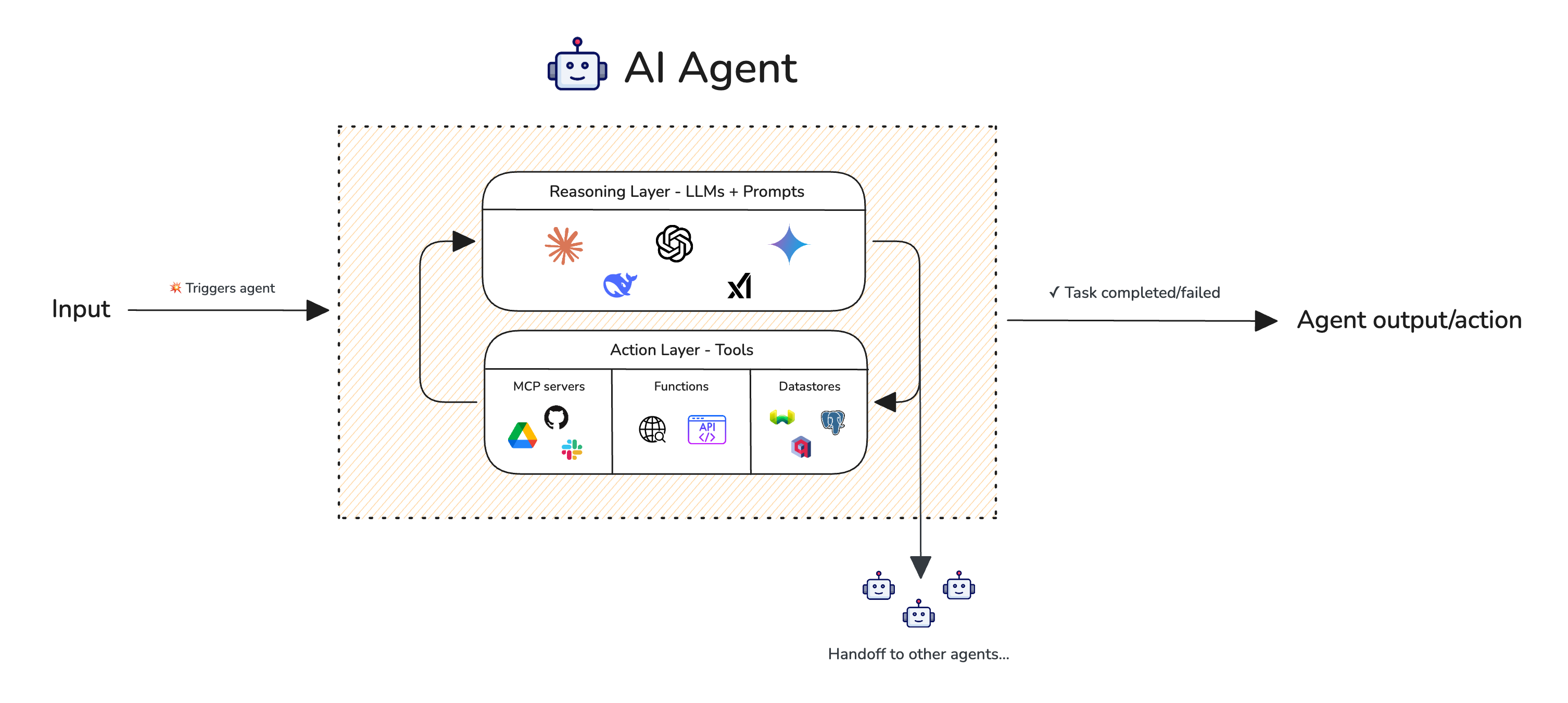
The reasoning layer contains your LLM and is responsible for understanding tasks, creating plans, and deciding which tools to use. The action layer contains your tools (function calls, APIs, etc.) and is responsible for executing those decisions. Together, they loop until the task is complete or fails.
Reasoning Layer
The reasoning layer, powered by your LLM, is responsible for planning and decision-making. This typically involves:
- Understanding the user's intent by analyzing the input to determine the underlying task and goals.
- Decomposing complex tasks into smaller, manageable sub-tasks that can be executed sequentially or in parallel.
- Creating a coherent strategy that outlines the steps needed to accomplish the task.
- Deciding which tools to use and in what order based on the current context.
The quality of your agent's reasoning is primarily affected by:
- LLM choice: Different models have varying reasoning capabilities. Larger models like
gpt-4oorclaude-3.5-sonnettypically reason better than smaller models, but at higher cost and latency. - Prompt template: The system prompt and instructions given to the LLM heavily influence how it approaches tasks. A well-crafted prompt guides the LLM to reason step-by-step, consider edge cases, and produce coherent plans.
- Temperature: Lower temperatures produce more deterministic, focused reasoning; higher temperatures may lead to more creative but potentially inconsistent plans.
Here are the key questions AI agent evaluation aims to solve in the reasoning layer:
- Is your agent creating effective plans? A good plan should be logical, complete, and efficient for accomplishing the task. Poor plans lead to wasted steps, missed requirements, or outright failure.
- Is the plan appropriately scoped? Plans that are too granular waste resources, while plans that are too high-level leave critical details unaddressed.
- Does the plan account for dependencies? Some sub-tasks must be completed before others can begin. A good plan respects these dependencies.
- Is your agent following its own plan? An agent that creates a good plan but then deviates from it during execution undermines its own reasoning.
Action Layer
The action layer is where your agent interacts with external systems through tools (function calls, APIs, databases, etc.). This is often where things go wrong. The action layer typically involves:
- Selecting the right tool from the available options based on the current sub-task.
- Generating correct arguments for the tool call based on the input and context.
- Calling tools in the correct sequence when there are dependencies between operations.
- Processing tool outputs and passing results back to the reasoning layer.
The quality of your agent's tool calling is primarily affected by:
- Available tools: The set of tools you expose to your agent determines what actions it can take. Too many tools can confuse the LLM; too few may leave gaps in capability.
- Tool descriptions: Clear, unambiguous descriptions help the LLM understand when and how to use each tool. Vague descriptions lead to incorrect tool selection.
- Tool schemas: Well-defined input/output schemas with proper types, required fields, and examples help the LLM generate correct arguments.
- Tool naming: Intuitive, descriptive tool names (e.g.,
SearchFlightsvsapi_call_1) make it easier for the LLM to select the right tool.
Here are the key questions AI agent evaluation aims to solve in the action layer:
- Is your agent selecting the correct tools? With multiple tools available, the agent must choose the one best suited for each sub-task. Selecting a
Calculatortool when aWebSearchis needed will lead to task failure. - Is your agent calling the right number of tools? Calling too few tools means the task won't be completed; calling unnecessary tools wastes resources and can introduce errors.
- Is your agent calling tools in the correct order? Some tasks require specific sequencing—you can't book a flight before searching for available options.
- Is your agent supplying correct arguments? Even with the right tool selected, incorrect arguments will cause failures. For example, calling a
WeatherAPIwith{"city": "San Francisco"}when the tool expects{"location": "San Francisco, CA, USA"}may return errors or incorrect data. - Are argument values extracted correctly from context? The agent must accurately parse user input and previous tool outputs to construct valid arguments.
- Are tool descriptions clear enough? Ambiguous or incomplete tool descriptions can confuse the LLM about when and how to use each tool.
Overall Execution
The overall execution encompasses the agentic loop where reasoning and action layers work together iteratively. This involves:
- Orchestrating the reasoning-action loop where the LLM reasons, calls tools, observes results, and reasons again.
- Handling errors and edge cases gracefully, adapting the approach when things don't go as expected.
- Iterating until the task is complete or determining that completion is not possible.
Here are some questions AI agent evaluation can answer about overall execution:
- Did your agent complete the task? This is the ultimate measure of success—did the agent accomplish what the user asked for?
- Is your agent executing efficiently? The agent should complete tasks without unnecessary or redundant steps. An agent that calls the same tool multiple times with identical arguments, or takes circuitous paths to simple goals, wastes time and resources.
- Is your agent handling failures appropriately? When a tool call fails or returns unexpected results, the agent should adapt rather than repeatedly trying the same failed approach.
- Is your agent staying on task? The agent should remain focused on the user's original request rather than going off on tangents or performing unrequested actions.
Agent Evals In Development
Evaluating agents in development is all about benchmarking with datasets and metrics. Your metrics will tackle either the reasoning or action layer, while datasets make sure you're comparing different iterations of your agents on the same set of goldens.
Development evals help answer questions like:
- Which agent version performs best? Compare different implementations side-by-side on the same dataset.
- Will changing a prompt affect overall success? Test prompt variations and measure their impact on task completion.
- Is my new tool helping or hurting? Evaluate whether adding or modifying tools improves agent performance.
- Where is my agent failing? Pinpoint whether issues stem from poor planning, wrong tool selection, or incorrect arguments.
But first, you'll have to tell deepeval what components are within your AI agent in order for metrics to operate. You can do this via LLM tracing. LLM tracing is a great way to help deepeval map out the entire execution trace of AI agents, and involves adding an @observe decorator to functions within your AI agent, and adds no latency to your AI agent.
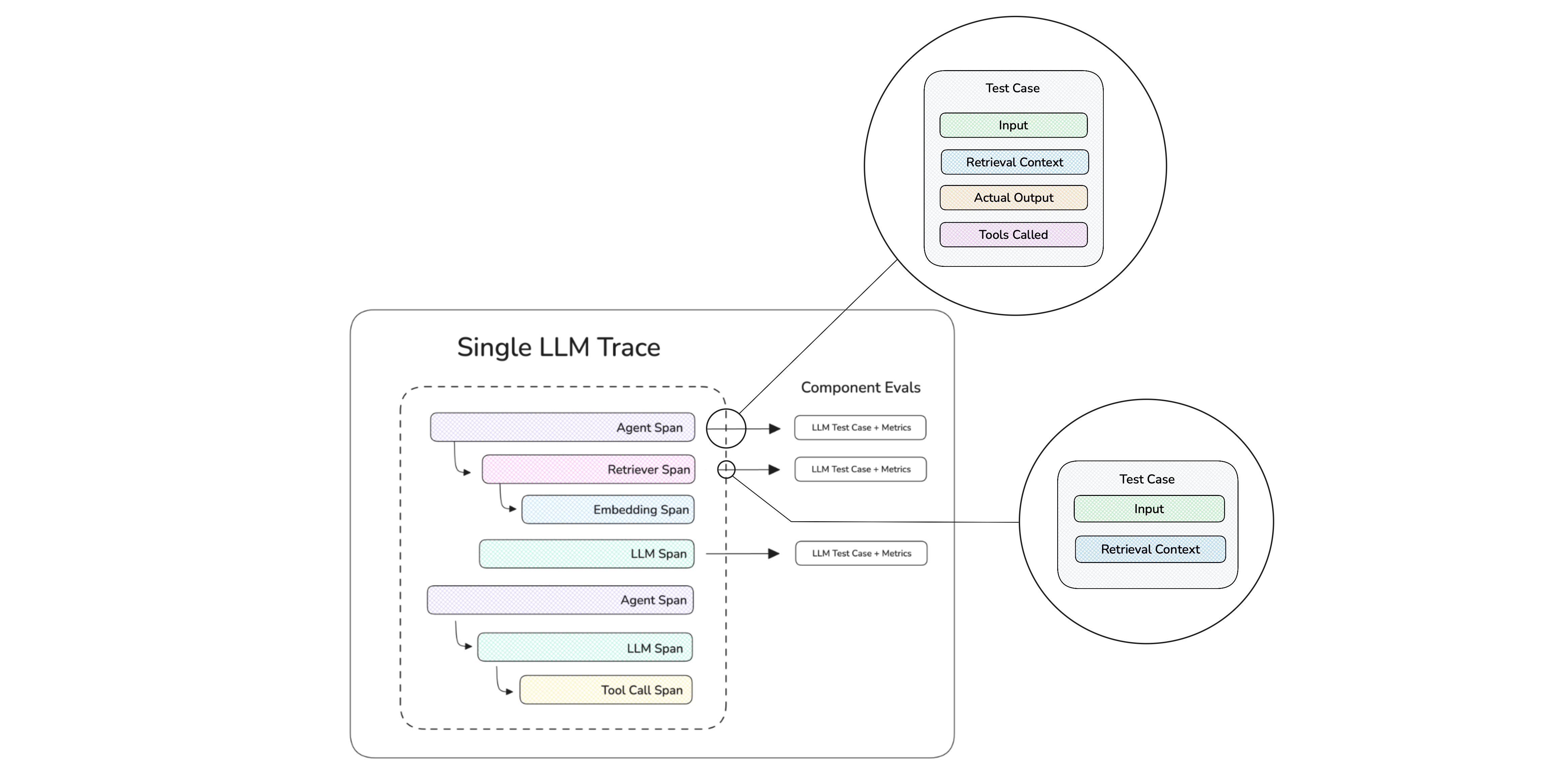
Let's look at the example below to see how we can setup tracing on an example flight booking agent that uses OpenAI as the LLM:
import json
from openai import OpenAI
from deepeval.tracing import observe
from deepeval.dataset import Golden, EvaluationDataset
client = OpenAI()
tools = [...] # See tools schema below
@observe(type="tool")
def search_flights(origin, destination, date):
# Simulated flight search
return [{"id": "FL123", "price": 450}, {"id": "FL456", "price": 380}]
@observe(type="tool")
def book_flight(flight_id):
# Simulated booking
return {"confirmation": "CONF-789", "flight_id": flight_id}
@observe(type="llm")
def call_openai(messages):
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools
)
return response
@observe(type="agent")
def travel_agent(user_input):
messages = [{"role": "user", "content": user_input}]
# LLM reasons about which tool to call
response = call_openai(messages)
tool_call = response.choices[0].message.tool_calls[0]
args = json.loads(tool_call.function.arguments)
# Execute the tool
flights = search_flights(args["origin"], args["destination"], args["date"])
# LLM decides to book the cheapest
cheapest = min(flights, key=lambda x: x["price"])
messages.append({"role": "assistant", "content": f"Found flights. Booking cheapest: {cheapest['id']}"})
booking = book_flight(cheapest["id"])
return f"Booked flight {cheapest['id']} for ${cheapest['price']}. Confirmation: {booking['confirmation']}"View OpenAI tools schema
tools = [
{
"type": "function",
"function": {
"name": "search_flights",
"description": "Search for available flights between two cities",
"parameters": {
"type": "object",
"properties": {
"origin": {"type": "string"},
"destination": {"type": "string"},
"date": {"type": "string"}
},
"required": ["origin", "destination", "date"]
}
}
},
{
"type": "function",
"function": {
"name": "book_flight",
"description": "Book a specific flight by ID",
"parameters": {
"type": "object",
"properties": {
"flight_id": {"type": "string"}
},
"required": ["flight_id"]
}
}
}
]In this example, we've decorated each component of our agent with @observe() to create a full execution trace:
@observe(type="tool")onsearch_flightsandbook_flight— marks these as tool spans, representing the action layer where the agent interacts with external systems.@observe(type="llm")oncall_openai— marks this as an LLM span, capturing the reasoning layer where OpenAI decides which tool to call.@observe(type="agent")ontravel_agent— marks this as the top-level agent span that orchestrates the entire flow.
When travel_agent() is called, deepeval automatically captures the nested execution: the agent span contains the LLM span (reasoning) and tool spans (actions), forming a tree structure that metrics can analyze.
Another thing that is recommended is logging into Confident AI — an AI quality platform deepeval integrates with natively. If you've set your CONFIDENT_API_KEY or run deepeval login, test runs will appear automatically on the platform whenever you run an evaluation as you will quickly learn,
Evaluating the Reasoning Layer
deepeval offers two LLM evaluation metrics to evaluate your agent's reasoning and planning capabilities:
-
PlanQualityMetric: evaluates whether the plan your agent generates is logical, complete, and efficient for accomplishing the given task. -
PlanAdherenceMetric: evaluates whether your agent follows its own plan during execution, or deviates from the intended strategy.
A combination of these two metrics is needed because you want to make sure the agent creates good plans AND follows them consistently. Evaluating the reasoning layer ensures your agent has a solid foundation before action begins. First create these two metrics in deepeval:
from deepeval.metrics import PlanQualityMetric, PlanAdherenceMetric
plan_quality = PlanQualityMetric()
plan_adherence = PlanAdherenceMetric()Finally, loop your traced AI agent over a dataset you've prepared while defining the PlanAdherenceMetric and PlanQualityMetric as an end-to-end metric:
from deepeval.dataset import EvaluationDataset, Golden
# Create dataset
dataset = EvaluationDataset(goldens=[
Golden(input="Book a flight from NYC to London for next Monday")
])
# Loop through dataset with metrics
for golden in dataset.evals_iterator(metrics=[plan_quality, plan_adherence]):
travel_agent(golden.input)The travel_agent in this example can be any @observe decorated agent. Whatever decorated function runs inside evals_iterator, deepeval will automatically collect the traces and run the specified metrics on them.
Congratulations 🎉! You've just learnt how to evaluate your AI agent's reasoning capabilities, lets move on to the action layer.
Evaluating the Action Layer
deepeval offers two LLM evaluation metrics to evaluate your agent's tool calling ability:
-
ToolCorrectnessMetric: evaluates whether your agent selects the right tools and calls them in the expected manner based on a list of expected tools. -
ArgumentCorrectnessMetric: evaluates whether your agent generates correct arguments for each tool call based on the input and context.
These are component-level metrics and should be placed strictly on the LLM component of your agent (e.g., call_openai), since this is where tool calling decisions are made. The LLM is responsible for selecting which tools to use and generating the arguments—so that's exactly where we want to evaluate.
To begin, define your metrics:
from deepeval.metrics import ToolCorrectnessMetric, ArgumentCorrectnessMetric
tool_correctness = ToolCorrectnessMetric()
argument_correctness = ArgumentCorrectnessMetric()Then, add the metrics to the LLM component of your AI agent:
# Add metrics=[...] to @observe
@observe(type="llm", metrics=[tool_correctness, argument_correctness])
def call_openai(messages):
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools
)
return responseLastly, run your traced AI agent with the added metrics:
from deepeval.dataset import EvaluationDataset, Golden
# Create dataset
dataset = EvaluationDataset(goldens=[
Golden(input="What's the weather like in San Francisco and should I bring an umbrella?")
])
# Evaluate with action layer metrics
for golden in dataset.evals_iterator():
weather_agent(golden.input)The tools_called contains the actual tools your agent invoked (with their arguments), and expected_tools defines what tools should have been called. Visit their respective metric documentation pages to learn how they're calculated:
Let's move on to evaluating the overall execution of your AI agent.
Evaluating Overall Execution
deepeval offers two LLM evaluation metrics to evaluate your agent's overall execution:
-
TaskCompletionMetric: evaluates whether your agent successfully accomplishes the intended task based on analyzing the full execution trace. -
StepEfficiencyMetric: evaluates whether your agent completes tasks efficiently without unnecessary or redundant steps.
These metrics analyze the full agent trace to assess execution quality:
from deepeval.metrics import TaskCompletionMetric, StepEfficiencyMetric
task_completion = TaskCompletionMetric()
step_efficiency = StepEfficiencyMetric()Lastly, same as above, run your AI agent with these metrics:
from deepeval.dataset import EvaluationDataset, Golden
# Create dataset
dataset = EvaluationDataset(goldens=[
Golden(input="Book the cheapest flight from NYC to LA for tomorrow")
])
# Evaluate with execution metrics
for golden in dataset.evals_iterator(metrics=[task_completion, step_efficiency]):
travel_agent(golden.input)The TaskCompletionMetric will assess whether the agent actually booked a flight as requested, while StepEfficiencyMetric will evaluate whether the agent took the most direct path to completion.
End-to-End vs Component-Level Evals
You might have noticed that we used two different evaluation approaches in the sections above:
-
End-to-end evals — The reasoning layer metrics (
PlanQualityMetric,PlanAdherenceMetric) and execution metrics (TaskCompletionMetric,StepEfficiencyMetric) were passed toevals_iterator(metrics=[...]). These metrics analyze the entire agent trace from start to finish. -
Component-level evals — The action layer metrics (
ToolCorrectnessMetric,ArgumentCorrectnessMetric) were attached directly to the@observedecorator on the LLM component via@observe(metrics=[...]). These metrics evaluate a specific component in isolation.
This distinction matters because different metrics need different scopes:
| Metric Type | Scope | Why |
|---|---|---|
| Reasoning & Execution | End-to-end | Need to see the full trace to assess overall planning and task completion |
| Action Layer | Component-level | Tool calling decisions happen at the LLM component, so we evaluate there |
You can learn more about when to use each approach in the end-to-end evals and component-level evals documentation.
Using Custom Evals
The agentic metrics covered above are useful but generic. What if you need to evaluate something specific to your use case—like whether your agent maintains a professional tone, follows company guidelines, or explains its reasoning clearly?
This is where GEval comes in. G-Eval is a framework that uses LLM-as-a-judge to evaluate outputs based on any custom criteria you define in plain English. It can be applied at both the component level and end-to-end level.
Evaluating AI agents In CI/CD
Once your agent passes in development, you'll want to guard against regressions on every push or PR. deepeval plugs into pytest via assert_test() and the deepeval test run command, so your agent evals run like any other test suite—locally in development, and automatically in CI/CD.
Instrument your agent based on your tech stack, then parametrize a pytest test over your goldens and call assert_test(). Since your agent is traced, deepeval builds each test case automatically—no manual extraction of inputs and outputs:
import pytest
from deepeval import assert_test
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
from deepeval.tracing import observe, update_current_trace
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
@observe()
def my_ai_agent(query: str) -> str:
answer = "Pi rounded to 2 decimal places is 3.14."
update_current_trace(input=query, output=answer)
return answer
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_llm_app(golden: Golden):
my_ai_agent(golden.input)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Wrap your agent's top-level function with @observe and set the trace-level test case fields with update_current_trace(...). See LLM tracing for the full surface.
import pytest
from langchain.agents import create_agent
from deepeval import assert_test
from deepeval.integrations.langchain import CallbackHandler
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
agent = create_agent(
model="openai:gpt-4o-mini",
tools=[],
system_prompt="Answer math questions concisely.",
)
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_langchain_app(golden: Golden):
agent.invoke(
{"messages": [{"role": "user", "content": golden.input}]},
config={"callbacks": [CallbackHandler()]},
)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Pass deepeval's CallbackHandler to your agent's invoke method. See the LangChain integration for the full surface.
import pytest
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START, END
from deepeval import assert_test
from deepeval.integrations.langchain import CallbackHandler
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
llm = init_chat_model("openai:gpt-4o-mini")
def chatbot(state: MessagesState):
return {"messages": [llm.invoke(state["messages"])]}
graph = (
StateGraph(MessagesState)
.add_node(chatbot)
.add_edge(START, "chatbot")
.add_edge("chatbot", END)
.compile()
)
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_langgraph_app(golden: Golden):
graph.invoke(
{"messages": [{"role": "user", "content": golden.input}]},
config={"callbacks": [CallbackHandler()]},
)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Pass deepeval's CallbackHandler to your StateGraph's invoke method. See the LangGraph integration for the full surface.
import pytest
from deepeval import assert_test
from deepeval.openai import OpenAI
from deepeval.tracing import trace
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent (drop-in replace `from openai import OpenAI`)
client = OpenAI()
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_openai_app(golden: Golden):
with trace():
client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Answer in one short sentence."},
{"role": "user", "content": golden.input},
],
)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Drop-in replace from openai import OpenAI with from deepeval.openai import OpenAI — every completion call becomes an LLM span automatically. See the OpenAI integration for the full surface.
import pytest
from pydantic_ai import Agent
from deepeval import assert_test
from deepeval.integrations.pydantic_ai import DeepEvalInstrumentationSettings
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
agent = Agent(
"openai:gpt-5",
system_prompt="Answer in one short sentence.",
instrument=DeepEvalInstrumentationSettings(),
)
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_pydantic_ai_app(golden: Golden):
agent.run_sync(golden.input)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Pass DeepEvalInstrumentationSettings() to your Agent's instrument keyword. See the Pydantic AI integration for the full surface.
import pytest
from bedrock_agentcore import BedrockAgentCoreApp
from strands import Agent
from deepeval import assert_test
from deepeval.integrations.agentcore import instrument_agentcore
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
instrument_agentcore()
app = BedrockAgentCoreApp()
agent = Agent(model="amazon.nova-lite-v1:0")
@app.entrypoint
def invoke(payload):
result = agent(payload["prompt"])
return {"result": result.message}
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_agentcore_app(golden: Golden):
invoke({"prompt": golden.input})
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Call instrument_agentcore() before creating your AgentCore app — it also instruments Strands agents running inside AgentCore. See the AgentCore integration for the full surface.
import pytest
from strands import Agent
from strands.models.openai import OpenAIModel
from deepeval import assert_test
from deepeval.integrations.strands import instrument_strands
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="Help me return my order.")])
# 2. Instrument your agent
instrument_strands()
agent = Agent(
model=OpenAIModel(model_id="gpt-4o-mini"),
system_prompt="You are a helpful assistant.",
)
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_strands_agent(golden: Golden):
agent(golden.input)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Call instrument_strands() before creating or invoking your agent (for AgentCore-hosted Strands, use the AgentCore tab). See the Strands integration for the full surface.
import pytest
from deepeval import assert_test
from deepeval.anthropic import Anthropic
from deepeval.tracing import trace
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent (drop-in replace `from anthropic import Anthropic`)
client = Anthropic()
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_anthropic_app(golden: Golden):
with trace():
client.messages.create(
model="claude-sonnet-4-5",
max_tokens=1024,
system="Answer in one short sentence.",
messages=[{"role": "user", "content": golden.input}],
)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Drop-in replace from anthropic import Anthropic with from deepeval.anthropic import Anthropic — every messages.create(...) call becomes an LLM span automatically. See the Anthropic integration for the full surface.
import asyncio
import pytest
from llama_index.llms.openai import OpenAI
from llama_index.core.agent import FunctionAgent
import llama_index.core.instrumentation as instrument
from deepeval import assert_test
from deepeval.integrations.llama_index import instrument_llama_index
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
instrument_llama_index(instrument.get_dispatcher())
agent = FunctionAgent(
tools=[],
llm=OpenAI(model="gpt-4o-mini"),
system_prompt="Answer math questions concisely.",
)
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_llamaindex_app(golden: Golden):
asyncio.run(agent.run(golden.input))
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Register deepeval's event handler against LlamaIndex's instrumentation dispatcher. See the LlamaIndex integration for the full surface.
import pytest
from agents import Runner, add_trace_processor
from deepeval import assert_test
from deepeval.openai_agents import Agent, DeepEvalTracingProcessor
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
add_trace_processor(DeepEvalTracingProcessor())
agent = Agent(
name="math_agent",
instructions="Answer math questions concisely.",
)
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_openai_agents_app(golden: Golden):
Runner.run_sync(agent, golden.input)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Register DeepEvalTracingProcessor once, then build your agent with deepeval's Agent shim. See the OpenAI Agents integration for the full surface.
import asyncio
import pytest
from google.adk.agents import LlmAgent
from google.adk.runners import InMemoryRunner
from google.genai import types
from deepeval import assert_test
from deepeval.integrations.google_adk import instrument_google_adk
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
instrument_google_adk()
agent = LlmAgent(model="gemini-2.0-flash", name="assistant", instruction="Answer math questions concisely.")
runner = InMemoryRunner(agent=agent, app_name="deepeval-google-adk")
async def run_agent(prompt: str) -> str:
session = await runner.session_service.create_session(app_name="deepeval-google-adk", user_id="demo-user")
message = types.Content(role="user", parts=[types.Part(text=prompt)])
async for event in runner.run_async(user_id="demo-user", session_id=session.id, new_message=message):
if event.is_final_response() and event.content:
return "".join(part.text for part in event.content.parts if getattr(part, "text", None))
return ""
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_google_adk_app(golden: Golden):
asyncio.run(run_agent(golden.input))
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Call instrument_google_adk() once before building your LlmAgent. See the Google ADK integration for the full surface.
import pytest
from crewai import Task
from deepeval import assert_test
from deepeval.integrations.crewai import instrument_crewai, Crew, Agent
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
# 1. Load your dataset of goldens
dataset = EvaluationDataset(goldens=[Golden(input="What is pi rounded to 2 decimal places?")])
# 2. Instrument your agent
instrument_crewai()
tutor = Agent(
role="Math Tutor",
goal="Answer math questions accurately and concisely.",
backstory="An experienced tutor who explains simple math clearly.",
)
task = Task(
description="{question}",
expected_output="Pi rounded to 2 decimal places is 3.14.",
agent=tutor,
)
crew = Crew(agents=[tutor], tasks=[task])
# 3. Evaluate end-to-end on each golden
@pytest.mark.parametrize("golden", dataset.goldens)
def test_crewai_app(golden: Golden):
crew.kickoff({"question": golden.input})
assert_test(golden=golden, metrics=[TaskCompletionMetric()])Call instrument_crewai() once, then build your crew with deepeval's Crew and Agent shims. See the CrewAI integration for the full surface.
Then run your test suite with deepeval test run, which layers LLM-specific features on top of pytest:
deepeval test run test_llm_app.pyDrop this command into a .yml workflow and failing metrics will fail the build, so agent regressions get caught before they ship. For the complete CI/CD walkthrough—including a ready-to-use GitHub Actions config—see the AI Agent Evaluation Quickstart.
Evaluating AI agents with coding assistants
More and more agents are being built by coding assistants like Claude Code. But here's the catch: a coding agent's harness — CLAUDE.md, hooks, skills, plugins, MCP servers — is built to get the right context into the model and ship good code. It has no native concept of measuring an agent's output against ground truth. A test is green or red, but there's no assertEqual for "was this response faithful?"
That gap is exactly what an eval harness fills, and DeepEval is the eval harness for AI agents. Because skills load on demand, dropping it into your coding agent is a one-liner:
npx skills add confident-ai/deepeval --skill "deepeval"From there, Claude Code can drive the whole loop itself — generate datasets, run deepeval test run, and inspect locally captured traces — turning "add evals and fix the failures" into something it can actually act on.
For the full picture of where the eval harness sits in the agent stack and how it plugs into a coding agent's own harness, read Eval harness: what it is, how to use it, and why you should care.
Agent Evals In Production
In production, the goal shifts from benchmarking to continuous performance monitoring. Unlike development where you run evals on datasets, production evals need to:
- Run asynchronously — never block your agent's responses
- Avoid resource overhead — no local metric initialization or LLM judge calls
- Track trends over time — monitor quality degradation before users notice
While you could spin up a separate evaluation server, Confident AI handles this seamlessly. Here's how to set it up:
Create a Metric Collection
Log in to Confident AI and create a metric collection containing the metrics you want to run in production:
Reference the Collection
Replace your local metrics=[...] with metric_collection:
# Reference your Confident AI metric collection by name
@observe(metric_collection="my-agent-metrics")
def call_openai(messages):
...That's it. Whenever your agent runs, deepeval automatically exports traces to Confident AI in an OpenTelemetry-like fashion—no additional code required. Confident AI then evaluates these traces asynchronously using your metric collection and stores the results for you to analyze.
Conclusion
In this guide, you learned that AI agents can fail at multiple layers:
- Reasoning layer — poor planning, ignored dependencies, plan deviation
- Action layer — wrong tool selection, incorrect arguments, bad call ordering
- Overall execution — incomplete tasks, inefficient steps, going off-task
To catch these issues, deepeval provides metrics you can apply at different scopes:
| Scope | Use Case | Example Metrics |
|---|---|---|
| End-to-end | Evaluate full agent trace | PlanQualityMetric, TaskCompletionMetric |
| Component-level | Evaluate specific components | ToolCorrectnessMetric, ArgumentCorrectnessMetric |
With proper evaluation in place, you can catch regressions before users do, pinpoint exactly where your agent is failing, make data-driven decisions about which version to ship, and continuously monitor quality in production.
FAQs
What is AI agent evaluation?
How is AI agent evaluation different from regular LLM evaluation?
Which AI agent metrics should I use in DeepEval?
PlanQualityMetric and PlanAdherenceMetric for reasoning, ToolCorrectnessMetric and ArgumentCorrectnessMetric for the action layer, and TaskCompletionMetric with StepEfficiencyMetric for end-to-end execution quality.What is the difference between end-to-end and component-level agent evals?
evals_iterator(metrics=[...]) and score the entire trace—best for plan quality and task completion. Component-level evals are attached via @observe(metrics=[...]) and score a specific span like the LLM tool-calling component—best for tool selection and argument correctness.Do I need tracing to evaluate AI agents?
@observe and the trace is built automatically.Can I write custom AI agent evaluation metrics?
GEval for subjective natural-language criteria like reasoning clarity or professional tone, and DAGMetric for deterministic decision-tree logic. Both can run end-to-end or be attached to a specific span.How do I run AI agent evaluation in production?
Next Steps And Additional Resources
While deepeval handles the metrics and evaluation logic, Confident AI is the platform that brings everything together. It solves the infrastructure overhead so you can focus on building better agents:
- LLM Observability — Visualize traces, debug failures, and understand exactly where your agent went wrong
- Async Production Evals — Run evaluations without blocking your agent or consuming production resources
- Dataset Management — Curate and version golden datasets on the cloud
- Performance Tracking — Monitor quality trends over time and catch degradation early
- Shareable Reports — Generate testing reports you can share with your team
Ready to get started? Here's what to do next:
- Login to Confident AI — Run
deepeval loginin your terminal to connect your account - Explore the metrics — Learn how each metric works, including calculation formulas and configuration options, in the AI Agent Evaluation Metrics guide
- Read the full guide — For a deeper dive into single-turn vs multi-turn agents, common misconceptions, and best practices, check out AI Agent Evaluation: The Definitive Guide
- Join the community — Have questions? Join the DeepEval Discord—we're happy to help!
Congratulations 🎉! You now have the knowledge to build robust evaluation pipelines for your AI agents.