Eval harness: What it is, how to use it, and why you should care
An eval harness is the infrastructure that runs your LLM evaluations end to end. Here's what it is, why it matters, and what a good one looks like.

To you and I, an agent harness is everything in 2026. For AI agents, an agent harness is everything in an agent that isn't the model. Think about memory, tool calling, API functions, and most importantly, evals. In other words, the infrastructure around the model that makes an AI agent work.
By simple deduction, you might think that an eval harness is as simple as the evaluation layer of an agent, correct? Well, not quite. Here is what I am here to talk about today.
What is an Eval Harness?
An evaluation harness is the validation layer for AI agents. Notice how it is for AI agents, not just the model. This might be conflicting, because didn't we just say that an eval harness is part of the agent harness, and that an agent harness wraps around the model?
To clarify: the agent harness isn't a single wrapper around the model, it's multiple layers handling tool orchestration, state persistence, error recovery, validation loops, and safety enforcement across an agent's lifecycle.
These layers fall into three tiers:
- Runtime: the core loop that keeps the model running, including prompt construction, output parsing, and error handling.
- Capabilities: what the agent can actually do, such as tools, memory, state, and context management.
- Assurance: the outermost guardrails, including subagent orchestration and validation loops.
Validation loops, in the assurance layer, are where the eval harness lives.
The Eval Harness is not what it seems
Before we continue, there is one thing I absolutely must clarify. An eval (same dataset, same metrics) can appear in two places:
- Offline / dev-time: runs against a fixed dataset, not on live traffic. This is the DeepEval loop and the CI gate. It's not in the runtime path of the agent serving a user. Nothing a real user sends touches it. This is genuinely "eval" in the pure sense: measuring behavior against ground truth, out of band.
- Online / runtime: runs on the actual request/response as the agent is serving it, and can act on the result — block the output, retry, escalate, fall back. The moment it's in the live path and gates the response, that's a guardrail, not an eval. The scoring mechanism might be identical (an LLM-judge, a faithfulness check), but its role changed. It's no longer measuring for your benefit; it's intercepting for the user's safety.
In practice the runtime version — the guardrail — is becoming a commodity: intercepting a bad output and retrying or falling back is increasingly off-the-shelf, and it really belongs to the error-handling part of the runtime layer, not here.
So now that we've determined that an eval harness is strictly for offline/dev-time validation, lets talk about how it works.
The Eval Harness is made up of metrics and datasets
At the center of the eval harness is the idea of a benchmark. Traditionally, academic benchmarks like MMLU and Big Bench Hard are benchmarks for foundational models. These were built for academic researchers to see how well their models are performing through popular projects such as LM Eleuther and Stanford HELM, not for AI engineers looping their AI agents.
But that doesn't mean the idea of benchmarking can't be applied to AI agents. When benchmarking an AI agent using an eval harness, we require two things:
Both of which are custom to your agentic use case. A single verification loop within an eval harness typically involves:
- Looping through your dataset of goldens
- For each golden within your dataset:
- Invoke your agent
- Collect the response, and execution trace if available
- Use all collected responses and traces to run your metric suite on it
Once completed, you now have a set of initial scores on how your agent performs on a particular dataset. Run this across multiple agent versions, and now you have a clear understanding of which agent of yours performs best.
Setting up an eval harness
DeepEval is the eval harness for AI agents, and so naturally it contains the means for you to generate or load existing datasets from knowledge bases, while providing 50+ ready to use LLM-as-a-judge metrics.
You can include it as a test file using DeepEval's native Pytest integration, that runs 100% in CI, and blocks a release if things start failing. Example below is an eval harness for a LangChain agent:
import pytest
from langchain.agents import create_agent
from deepeval import assert_test
from deepeval.integrations.langchain import CallbackHandler
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
agent = create_agent(model="openai:gpt-4o-mini", tools=[multiply], system_prompt="Be concise.")
dataset = EvaluationDataset(goldens=[
Golden(input="What is 8 multiplied by 6?"),
Golden(input="What is 7 multiplied by 9?"),
])
@pytest.mark.parametrize("golden", dataset.goldens)
def test_langchain_agent(golden: Golden):
agent.invoke(
{"messages": [{"role": "user", "content": golden.input}]},
config={"callbacks": [CallbackHandler()]},
)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])deepeval test run test_langchain_agent.pyYou can jump ahead and get started here, but do first finish the article because it's about to get interesting.
The Eval Harnesses behaves differently based on who uses it
No, I don't literally mean who runs your eval harness. The engineering intern, your engineering manager, your manager's manager, you, none of that.
I mean coding agents like Claude Code.
Understanding the Claude Code harness
Quick detour, because the next part borrows Claude Code's vocabulary and it's worth getting straight first. Anthropic has a good write-up on this if you want the full version.
Remember how we said an agent harness is everything around the model that makes it work? Claude Code has its own version of exactly that — the scaffolding Anthropic wraps around the model so it can navigate a codebase and write good code. Their framing is blunt about it: the harness matters as much as the model. A weaker model in a well-built harness beats a stronger model running naked.
That harness is built from a handful of named extension points, each loading at a different time:
| Component | What it is | When it loads |
|---|---|---|
CLAUDE.md | Context files Claude reads automatically — project conventions, gotchas | Every session |
| Hooks | Scripts that fire at set moments; enforce rules deterministically | Triggered by an event |
| Skills | Packaged instructions for a specific task type, loaded only when relevant | On demand |
| Plugins | Skills + hooks + MCP configs bundled into one installable package | Once installed, always available |
| MCP servers | Connections to external tools and data the model can't otherwise reach | Once configured, always available |
Here's a real example, from a single Claude Code session:
- Session starts → CLAUDE.md loads. Claude automatically reads the root file for the big picture and walks down subdirectory files for local conventions — before you've even typed your task.
- Start hook fires (optional). A start hook can inject team- or module-specific context dynamically, so the session is set up for the right part of the codebase without manual config.
- You prompt → skills load on demand. Claude matches the task to a relevant skill and pulls in that specialized workflow only when needed — a security-review skill for a vuln check, a deploy skill scoped to the payments directory, etc.
- Claude works → LSP + MCP servers do the reaching. As it navigates, LSP gives symbol-level precision ("go to definition," "find references") instead of text guessing, and MCP servers let it pull from internal tools, docs, or search it couldn't otherwise touch. Heavy exploration can be handed to a subagent that returns just the findings.
- Action happens → hooks enforce. On events like a file write or commit, hooks run deterministic checks (lint, format, tests) — rules that run whether or not Claude remembers them.
- Session ends → stop hook reflects. A stop hook can review what happened and propose CLAUDE.md updates while context is fresh, making the setup self-improving for next time.
Notice what's NOT in that table: anything resembling an eval. The Claude Code harness is built to get the right context into the model and shape what it does. It has no native concept of measuring the output against ground truth.
This is a big deal because, although Claude Code's own harness requires concepts of Skills and Hooks - there exists no eval harness for Claude Code building AI agents, not deterministic software.
For those vibe coding AI agents - this should be moderately concerning.
Using DeepEval as Claude Code's (or any coding agent's) Eval Harness
For most of what Claude Code writes, that's fine — the output is deterministic. A test is green or red; a hook can check for it. But building an AI agent breaks that.
There's no assertEqual for "was this response faithful?" The output is non-deterministic — the one thing hooks and lint can't catch. Claude Code's harness can validate the software it writes, but not the agent it writes.
Let's take a look how the regular eval harness DeepEval provides from this section above maps into Claude Code's harness:
| Claude Code component | Its job in the CC harness | What DeepEval puts here | Eval or guardrail? |
|---|---|---|---|
| Skill | Loads specialized expertise on demand when the task calls for it | The DeepEval skill — templates, the 50+ metric catalog, and the iteration-loop guardrails the agent follows when you say "add evals and fix the failures" | Eval — offline, agent-driven |
| Hook | Fires deterministically on an event, whether the agent remembers or not | deepeval test run wired to a stop or pre-commit hook, so green metrics become a gate rather than a suggestion | Eval — offline, enforced |
| Plugin | Bundles skills + hooks + MCP configs to distribute a setup across the team | The skill + eval hook + dataset packaged once, installed org-wide so the loop isn't tribal | Eval — distributed |
If this sounds complicated, it isn't. Note that skills load on demand, and so really all you need to do to have an eval harness setup is to install the DeepEval skill:
npx skills add confident-ai/deepeval --skill "deepeval"Under the hood, DeepEval chains together a series of CLI commands that makes up your eval harness that Claude Code's harness can take advantage of. This includes deepeval generate to generate datasets if you don't already have some, and deepeval test run to run the eval suite based on your preference of metrics.
Traces are also automatically captured on your machine in a local .json file. Instead of offloading your agent's execution traces to somewhere else, CC can run deepeval inspect to view traces directly to avoid overfitting metrics.
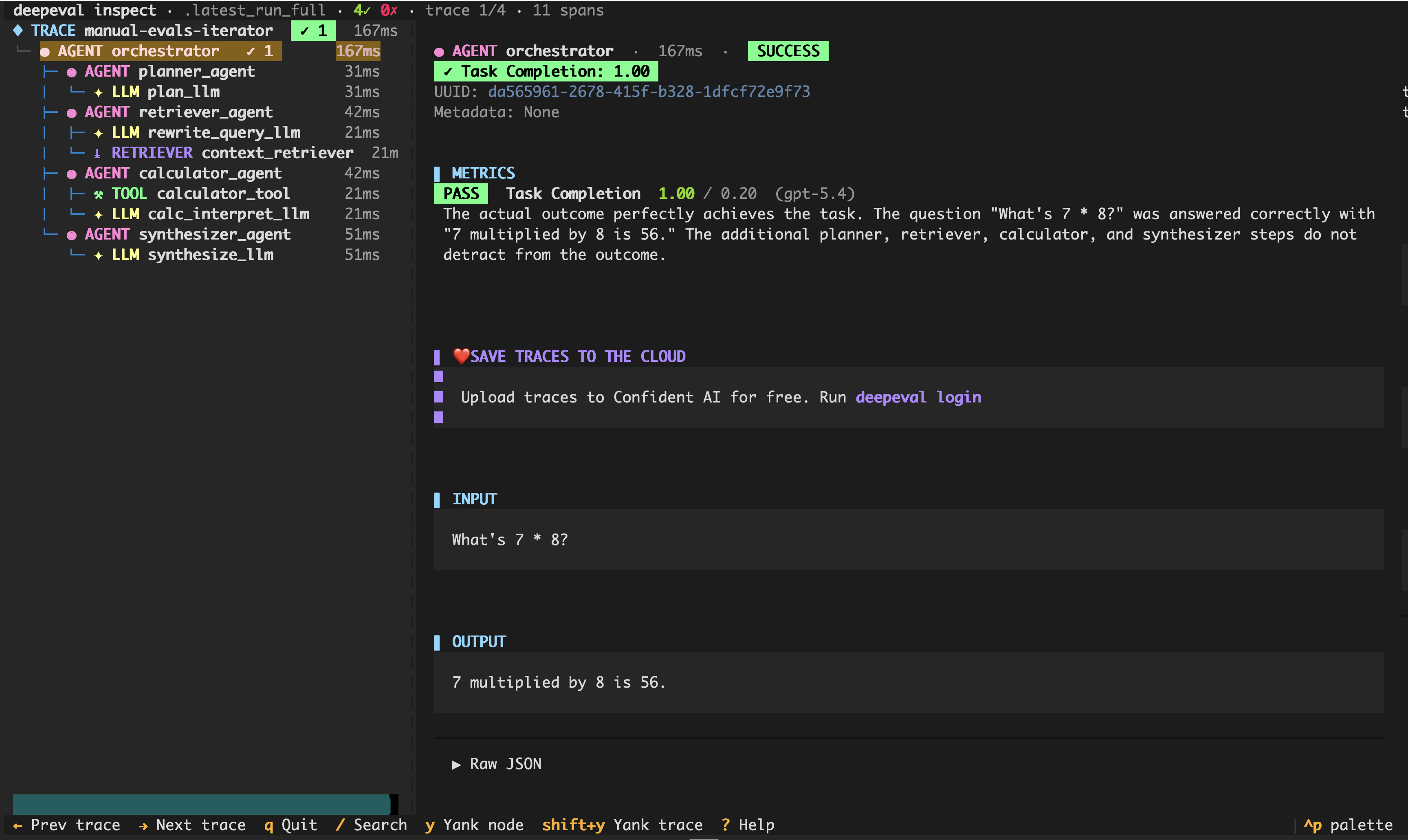
Conclusion: The harness that builds the eval harness
There's something a little odd about where we ended up. We started with the agent harness being everything around the model — memory, tools, evals — and then called the eval harness the validation layer for the agent that harness produces. When Claude Code reaches for DeepEval to build an agent, those two definitions collapse into each other: one coding agent is using a harness to check the agent it's writing.
It's worth noticing how that's different from everything else Claude Code does. The rest of its harness is about getting the right context in and good code out. None of it has an opinion on whether the agent that came out actually behaves. That's the gap the eval harness fills, and it happens to be the one place a passing test tells you nothing, because "was this response faithful?" isn't something lint or a unit test can answer.
I think this matters more as the models converge. When everyone has access to roughly the same frontier model, the harness around it is what's left to differentiate on, and evals are the part of that harness that decides what you actually ship. You're not shipping whatever the model wrote on the first pass. You're shipping the version that survived the evals — and that's a deliberate choice you make, not a side effect of the model being good.
DeepEval is free and 100% open-source on ⭐ GitHub.
FAQs
What is an eval harness?
What's the difference between an eval and a guardrail?
How is an eval harness different from an agent harness?
Does Claude Code have a built-in eval harness?
CLAUDE.md, hooks, skills, plugins, and MCP servers — is built to get the right context into the model and shape what it does. It has no native concept of measuring an output against ground truth. That's fine for deterministic code (a test is green or red), but it can't answer non-deterministic questions like "was this response faithful?" — which is exactly the gap an eval harness like DeepEval fills.How do I add DeepEval as an eval harness to a coding agent?
npx skills add confident-ai/deepeval --skill "deepeval". Under the hood it chains CLI commands — deepeval generate for datasets, deepeval test run for the metric suite, and deepeval inspect to view locally captured traces.Do I need Confident AI to use DeepEval?
.json file. Confident AI is optional and useful when you want shared reports, regression tracking, and production monitoring.LLM-as-a-Judge in 2026: Top evaluation techniques and best practices
LLM-as-a-Judge uses an LLM to score, classify, or compare another LLM's outputs. Here's what it is, the main techniques, and best practices for reliable evaluation.
Eval Driven Development: What it is, how to do it right, and real examples to learn from
Eval driven development is the practice of building LLM applications around evals first. Here's what it is, how to do it right, and the common mistakes to avoid.