Introducing DeepEval 4.0 - Evaluation Harness for Vibe Coding Agents
DeepEval 4.0 is a major release where the focus lies in integrating with users' existing stack.

Today, we're proud to announce our biggest and boldest major release yet, DeepEval 4.0, where the focus is on reliability. Just kidding, there are tons of new features in store for 4.0.
Since releasing DeepEval 3.0 in May of last year, a lot has happened: Claude code was born, agent orchestration frameworks became more stable, and developers are vibe coding agents more than ever.
This also means DeepEval's role in the AI development lifecycle needed a change. This is what this release is all about.
But first, how did we get here?
DeepEval started 2 years ago as "unit testing for LLMs", and in a way it still is, but it has grown way more than that. First users wanted plug and play metrics, so we standardized the API for evals via our BaseMetric and BaseConversationalMetrics, with a modular metric.measure(...) for anyone to embed in their eval workflows.
Then came the users without datasets, so we released a dataset Synthesizer, alongside a ConversationSimulator that helped users evaluate multi-turn agents without cold starts.
But today, the question users have isn't just "How do I use DeepEval as a test suite to evaluate agents?", or "I don't have a dataset, can I still run evals?", but more along the lines of: "I'm using LangChain/Pydantic/etc., how does DeepEval help me improve my agentic workflows?"
An eval harness for vibe coding agents
Something that is more true than ever in 2026 is that vibe coding is as big as ever. So for DeepEval 4.0, the first thing we did was include the necessary CLI commands for Claude Code, Codex, Cursor, etc. to use DeepEval.
This includes the generate CLI command that auto synthesizes datasets by inferring your use case from your codebase, the test run command to execute your test suites, and a local file storage system for coding agents to inspect results to run the next iteration loop.
Coding Agent
Cursor · Claude Code · Codex
Your AI App
Agent · RAG · Chatbot
deepeval test run
50+ metrics, one CLI
Scored Trace
Span-level scores + reasons
Together, these are glued as one using the latest agent SKILLs that we released here..
For users of DeepEval, this means that instead of asking Claude Code to guess what improvements you should make, DeepEval tells you what should be done instead, using the foundation of the primitives we've built up across 1.0, 2.0, 3.0, and now 4.0.
This is why we call DeepEval 4.0 the evaluation "harness" - it is the scaffolding that stops your vibe coding agents from vibe coding agents.
Give it a spin here.
Iterate without overfitting metrics
As any sane computer scientist might wonder - wouldn't Claude Code just overfit metrics that it has "arbitrarily" defined?
And that's not wrong at all, in fact that's a very legitimate concern. We've run DeepEval 4.0 internally for a few weeks and found that there were two main ways to help vibe coding agents understand what to actually improve (apart from metric scores):
- Annotations to align metrics
- Traces, to understand agent trajectory
Annotations should be obvious enough, but even with annotations no metric or combination of metrics can be perfect.
That's why tracing is so important - tracing makes sense of failing metrics instead of deferring back to speculation. In DeepEval 4.0, we believe that local iteration is the key forward - coding agents work best when it's local because it's fast, and latency for streaming is virtually 0 from a DX perspective.
Hence, our latest file storage system now stores traces, where when implemented would be accessible via a simple vi command, or, if humans would like to inspect the traces, deepeval inspect.
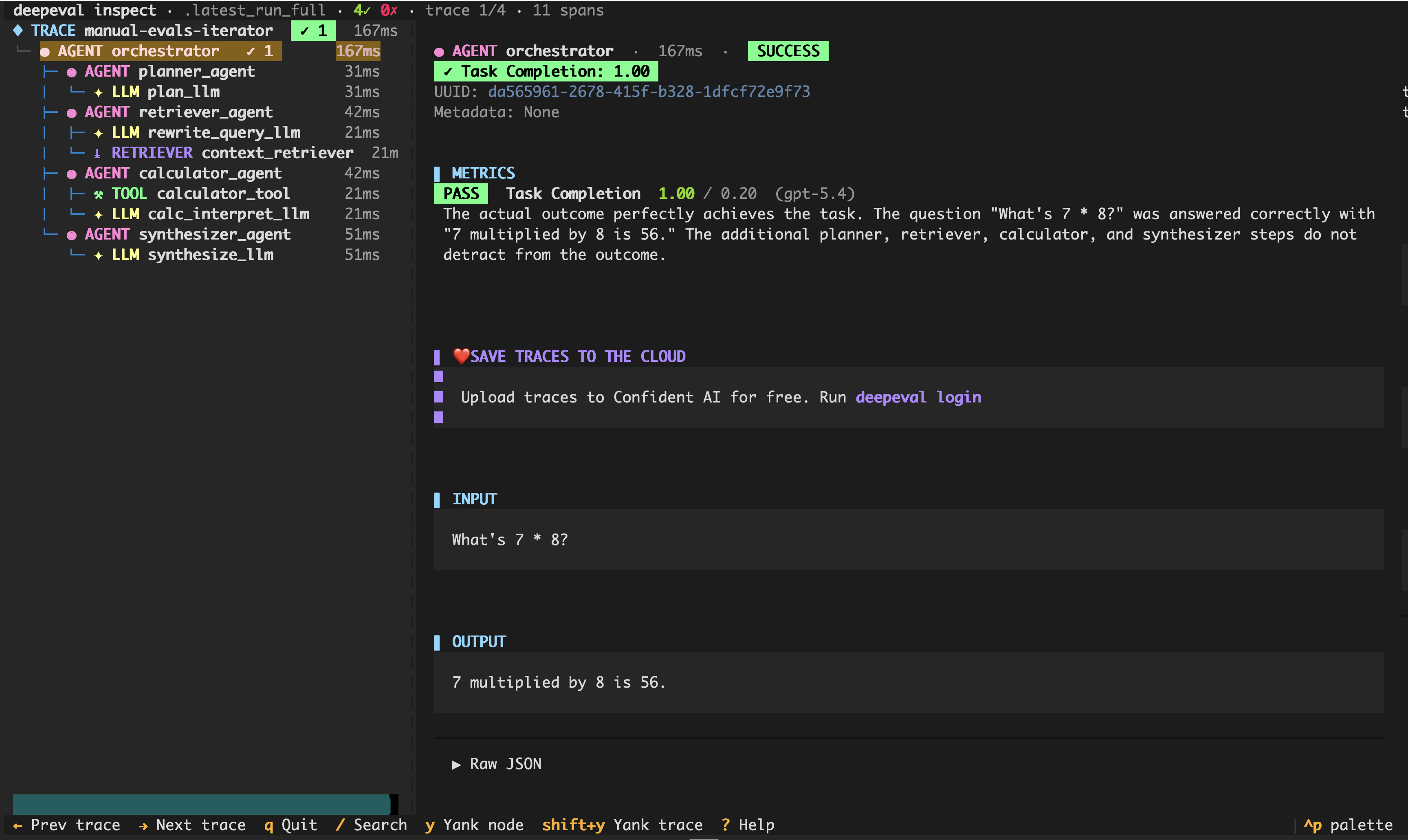
Yes, we released a local trace viewer for your evaluation suite, which sounds suicidal given our enterprise offering is a UI platform. That's how much we believe in a fully localized workflow.
Native tracing and evals for agentic frameworks
At the start of this post, I talked about how agent orchestration frameworks are getting more stable and mature than ever. That's also why we think users are getting more and more embedded in frameworks, and therefore so should DeepEval 4.0.
So today, we're releasing 1-line integrations with what we think are the current most popular frameworks for building agents (and if we missed you, it must be a mistake, please reach out on our discord so we can do your framework justice). This includes:
- LangChain/graph
- Pydantic AI
- OpenAI Agents
- Strands
- Agentcore
- Google ADK
- and a lot more
These integrations mean that you can trace and evaluate entire agents in 1 line of code. Let's take LangChain for example. Say you want a local evaluation suite that runs in CI/CD — this is how you'd do it with DeepEval in 4.0:
import pytest
from langchain.agents import create_agent
from deepeval import assert_test
from deepeval.integrations.langchain import CallbackHandler
from deepeval.dataset import EvaluationDataset, Golden
from deepeval.metrics import TaskCompletionMetric
def multiply(a: int, b: int) -> int:
return a * b
agent = create_agent(model="openai:gpt-4o-mini", tools=[multiply], system_prompt="Be concise.")
dataset = EvaluationDataset(goldens=[
Golden(input="What is 8 multiplied by 6?"),
Golden(input="What is 7 multiplied by 9?"),
])
@pytest.mark.parametrize("golden", dataset.goldens)
def test_langchain_agent(golden: Golden):
agent.invoke(
{"messages": [{"role": "user", "content": golden.input}]},
config={"callbacks": [CallbackHandler()]},
)
assert_test(golden=golden, metrics=[TaskCompletionMetric()])That's it - 1 line of code to add the CallbackHandler(metrics=[TaskCompletionMetric()]) on your agentic trace for local evaluation. All you have to do is run it with deepeval test run (our native Pytest integration):
deepeval test run test_langchain_agent.pyCombined with the evaluation harness workflow, this means you could get more work done while using fewer tokens. Include this command in a YAML file, and you have regression testing setup in CI/CD.
Other notable mentions
Although I said reliability as a core focus is a joke, we definitely don't treat reliability as one. Being an open-source package, once the release is out, it might get used and pinned to a certain version for who knows how long - so through 3.0 - 4.0, we've made incrementally meaningful changes to reliability around concurrency, threading, error handling, and more.
Another thing we added was prompt optimization algorithms like GEPA - however, I still consider those to be in BETA — despite being fully functional — because they currently work only on single prompts. Till we add tracing for it, we won't be talking about it too much.
What's next for DeepEval?
The way we ship at DeepEval has been 80% PRs from the internal team, and 20% from community. We believe with the latest 4.0 release, where reliability is much better accounted for, we're in a position to accept more community PRs.
Hence, on one hand we will continue with our roadmap, which is deeper integrations with coding tools, coding environments, and agent frameworks, while accepting metrics, integrations, etc. from the community — keeping that separation clear.
Thank you for being a user and as always, till next time.
We're releasing TypeScript in DeepEval's Python monorepo
DeepEval is going TypeScript. Here's why we put it in the same repo as Python, and how we keep the two implementations from drifting apart.
DeepEval Got a New Look
An announcement on DeepEval reaching 15,000 GitHub stars and the launch of a new docs and website experience for developers.