Design Philosophy
DeepEval was designed around around a simple idea: evaluation should fit the way your team actually iterates.
Local-first
Run evals in your own environment, against the code, datasets, and traces you are actively editing.
Pytest-native
Turn LLM quality into tests you can rerun locally, automate in CI, and trust during refactors.
Trace-aware
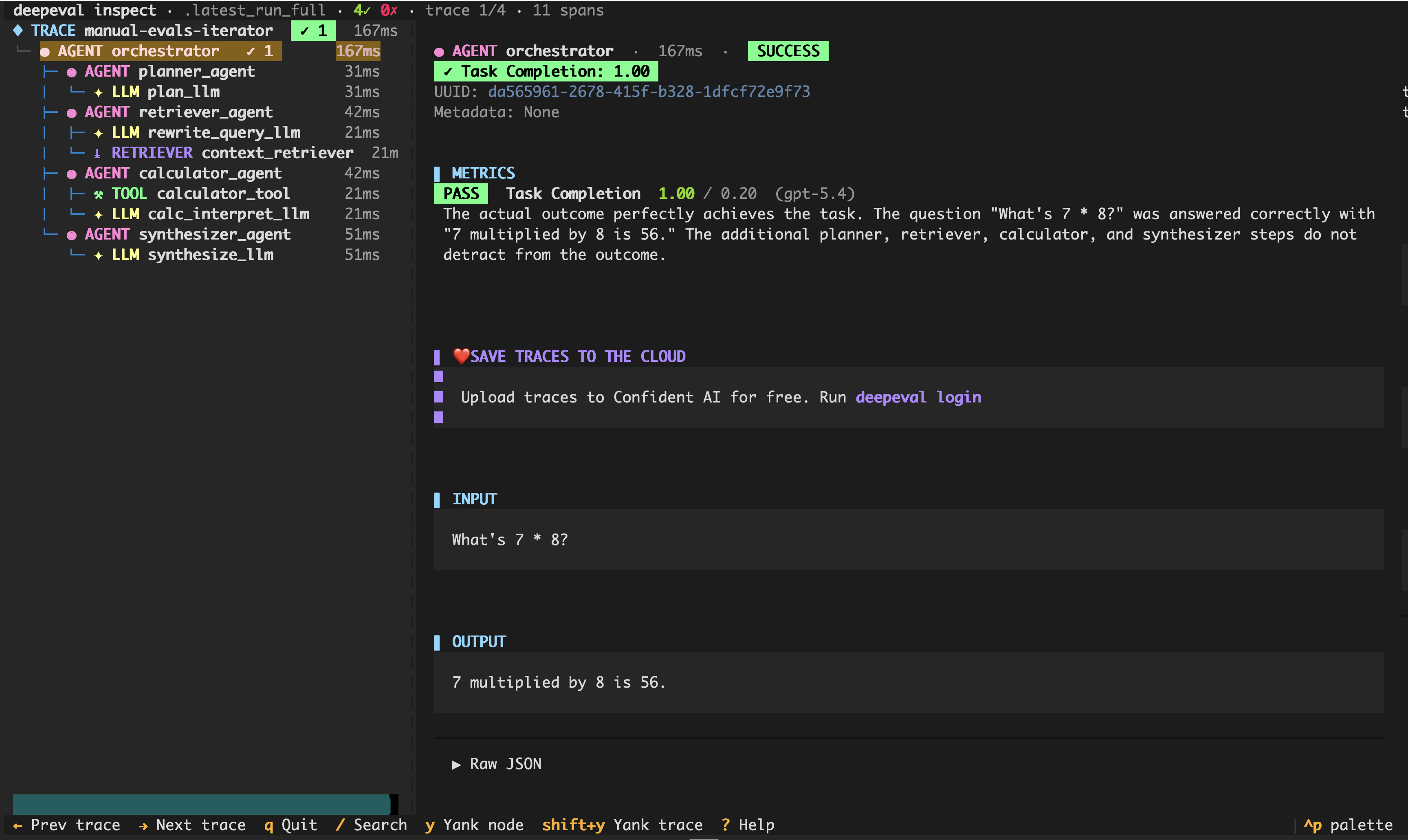
Use traces when you need to see which tool call, planner step, retriever, or generator caused a regression.
Composable
Combine datasets, metrics, traces, custom models, QA workflows, and coding-agent loops instead of buying into one rigid process.
Modular By Design
DeepEval gives you the building blocks to assemble your own eval pipeline:
- Test cases: structure the inputs, outputs, expected behavior, context, tools, and metadata you want to evaluate.
- Datasets: organize reusable goldens for regression tests, experiments, and CI/CD.
- Metrics: define how outputs, traces, and spans are scored.
- Traces and spans: capture what happened during execution so you can evaluate full runs or individual components.
- Synthetic data generation: generate test data when you do not have enough examples yet.
You can use them together through DeepEval's built-in workflows, or compose them yourself when your system needs something more specific. The framework is opinionated enough to make evals repeatable, but it does not force you into one rigid pipeline.
No More Vibe Coding AI
For vibe coders building AI, DeepEval is the validation layer in your iteration loop.
Instead of asking Claude Code, Codex, etc. to change your agent runtime from LangChain to Pydantic AI, or switch a model and modify a prompt, DeepEval gives you qualitative results required so coding agents can automate the iteration loop on auto-pilot.
Coding Agent
Cursor · Claude Code · Codex
Your AI App
Agent · RAG · Chatbot
deepeval test run
50+ metrics, one CLI
Scored Trace
Span-level scores + reasons
We hope that you can build reliable agents while grabbing a cup of coffee, even when vibe coding.
Rapid Local Iteration
For engineers, the fastest loop is local: run the agent, inspect the trace, identify the failing span, patch the prompt or code, and run the eval again.
That loop starts locally, where iteration is fastest. When your team needs to collaborate on results, compare regressions, monitor production traces, or share reports with non-engineers, DeepEval integrates natively with Confident AI.
Flexible Evaluation Models
DeepEval is designed around two complementary models. Both can produce end-to-end evals, and both can support component-level evals when you need more granularity.
Test Case-Based Evals
Use this when you already know the input and expected behavior. This is the most direct path for QA workflows, regression suites, CI/CD gates, and end-to-end output quality checks. You can also create component-level test cases manually when you want to evaluate a specific part of the system.
Trace-Based Evals
Use this when you can run the application and want to score what happened during execution: full traces, individual spans, tool calls, and agent steps. This is the natural path for AI agents, tool-using systems, and multi-step applications where the final answer is not enough to explain the failure.
The goal is not to choose one forever. Start with test cases when you need a simple quality gate. Add traces when you need to understand how your application arrived at the result.
Pytest-Native
DeepEval has first-class Pytest integration. You can write evals beside your application code, run them locally, and use pass/fail results in CI/CD. Evals can start as quick experiments, then become regression tests that protect future changes.
Because results can be saved locally, agentic coding tools can also inspect the same artifacts you do: failing metrics, reasons, traces, and test runs. That makes evals usable not only by humans, but by the tools helping you edit the agent.
No Cold-Starts
Good evals need examples. Without a dataset, it is hard to know whether a prompt, model, or agent change actually improved quality, or whether it only worked for the one example you happened to test manually.
When you do not have enough examples yet, synthetic data generation helps you bootstrap a dataset from documents, contexts, or seed examples. This lets you cover edge cases before users find them, instead of waiting for enough production traffic or manual QA cycles to build coverage.
Enterprise Platform When Needed
Local iteration should stay fast, but teams eventually need shared reports, regression analysis, trace observability, production monitoring, dataset management, prompt versioning, and collaboration with non-engineers.
DeepEval integrates natively with Confident AI
for those workflows, with 0 lines of additional code required. The same evals you run locally can become shared test runs,
experiments, dashboards, and monitoring jobs when your team needs a platform, all you have to do is export a CONFIDENT_API_KEY.
Opinionated Primitives, Simple API
AI is fast-moving, so evals need stable concepts underneath them. DeepEval keeps
the primitives opinionated: test cases describe what happened, metrics describe
how to score it, and assert_test() turns the result into a test.
The same primitives scale from one test case to datasets, traces, spans, and production monitoring.
If you are ready to run your first eval, start with the 5 min Quickstart.