Comparisons
This guide is useful both for those thinking of adopting or switching to DeepEval.
If you judge a fish by its ability to climb a tree, it will live its whole life believing that it is stupid.
Below are some non-detailed reasons why you may want to use DeepEval for fast local evaluation and iteration of AI agents and LLM apps.
vs Other Eval Libraries
- Widely adopted - DeepEval is used by teams at companies like Google, OpenAI, Microsoft, and other leading AI organizations.
- Agent-first evals - DeepEval supports traditional output scoring, but is especially strong for AI agents, tool calls, traces, spans, MCP systems, and multi-step workflows.
- Fast local loop - Run evals locally while changing prompts, tools, models, or code, then inspect failures without leaving your development workflow.
- Modular primitives - Build your own eval pipeline from test cases, datasets, metrics, traces, spans, custom models, and synthetic goldens.
- Largest eval metric library - Start with one of the broadest libraries of ready-to-use LLM evaluation metrics instead of assembling scattered scorers.
- Pytest and CI/CD - Turn evals into pass/fail tests that fit existing engineering workflows.
- Research-backed metrics - Use custom LLM-as-a-judge metrics like G-Eval, alongside RAG, agent, safety, conversational, and multimodal metrics.
- Native platform path - Start open-source and local, then scale to shared reports, regression analysis, observability, and monitoring with Confident AI.
- Proprietary evaluation techniques - Go beyond prompt-only scoring with DeepEval-native techniques like DAG, which lets you build deterministic, decision-graph-based evals.
vs LLM Observability Platforms
- Local iteration first - Run evals while you code, without waiting on a hosted dashboard or production telemetry pipeline.
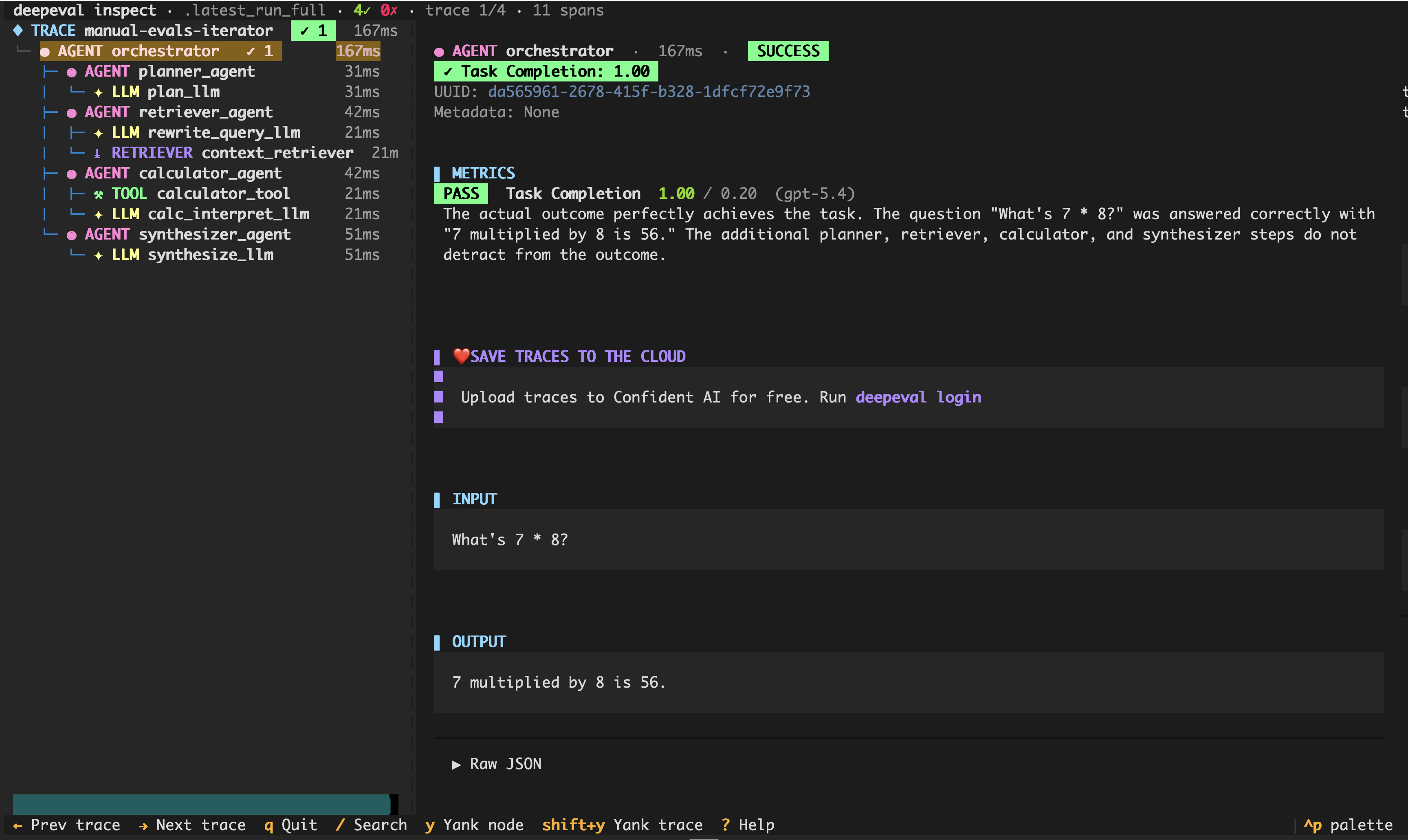
- Local traces - Inspect traces and spans from development runs, including tool calls, planners, retrievers, generators, and other agent components.
- Evaluation-first - DeepEval is built around metrics, test cases, datasets, traces, and CI/CD gates, not only logs and dashboards.
- Pytest-native - Add pass/fail evals to the same workflows you already use for software tests.
- Agentic coding tools - Save eval results locally so tools like Cursor or Claude Code can inspect failures, compare runs, and help iterate on prompts or code.
- Cloud when needed - Keep local development simple, then use Confident AI for shared reports, regression tracking, observability, and monitoring.
Net effect: edit → rerun → deepeval inspect in under a second, no dashboard round-trip.
PS. DeepEval also allows you to view traces locally on your machine.
vs RAG-Only Evaluation Libraries
- Agents beyond RAG - DeepEval supports RAG, but also evaluates agents, MCP systems, chatbots, tool-use workflows, LLM arenas, and custom applications.
- Trace and span evals - Score individual runtime components instead of only evaluating final answers or retrieval quality.
- Faster debugging loop - Run a trace locally, inspect which span failed, and update the agent without switching tools.
- More metric coverage - Use RAG metrics alongside agent, conversation, safety, multimodal, task completion, and custom metrics.
- Testing workflow - Run evals through Pytest, CI/CD, local scripts, or production trace evaluation.
- Synthetic data generation - Generate goldens for edge cases when manually curated datasets are not enough.
vs Prompt/Experiment Platforms
- Code-first control - Keep eval logic, metrics, datasets, and traces close to your application code.
- Fast prompt and tool iteration - Change a prompt, tool schema, model, or agent step, then rerun the same eval immediately.
- Custom metrics - Write your own metrics or customize built-in LLM-as-a-judge prompts instead of relying only on platform-provided scoring.
- Repeatable regression tests - Turn experiments into tests that block low-quality prompt, model, or agent changes before they ship.
- AI coding-agent friendly - Local JSON results and test files give coding agents concrete artifacts to read, compare, and edit against.
- Works with your stack - Bring your own model providers, app framework, tools, retrievers, and CI provider.
vs Rolling Your Own Evals
- Metrics built in - Start with 50+ metrics instead of building every scorer from scratch.
- Tracing built in - Capture traces and spans without designing your own evaluation data model.
- Local display built in - See eval results and trace-linked failures during development instead of building your own reporting loop.
- Dataset primitives - Reuse goldens across prompts, models, releases, and system variants.
- CI/CD ready - Use
deepeval test runto turn evals into deployment gates. - Production path - Move from local evals to shared reporting and monitoring without rewriting your evaluation workflow.