Evaluating Your Summarizer
In the previous section, we built a meeting summarization agent that:
- Generates summaries
- Generates action items
To evaluate an LLM application like a summarization agent, we'll use single-turn LLMTestCases from deepeval
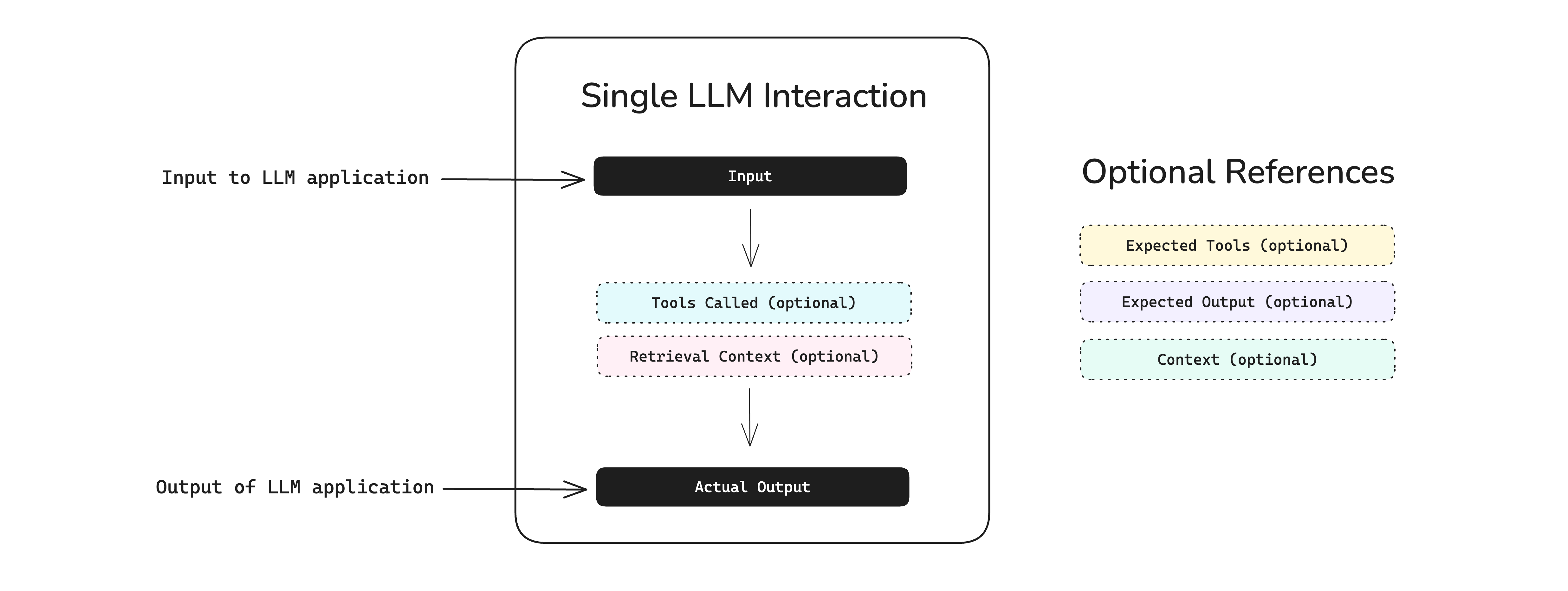
Our summarization agent is a single-turn LLM application. That means we supply a transcript as input, the agent generates a summary and a list of action items as output. In code, such unit interactions are represented by an LLMTestCase:
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="...", # Your transcript
actual_output="..." # The summary or action items
)Setup Testing Environment
For evaluating a summarization agent like ours, there is one main approach we can use:
- Use Datasets - Pull transcripts of previous meetings from a database or dataset. Since you're building a meeting summarizer, you might already have meeting transcripts that you want to summarize. You can store these transcripts in a database and retrieve them anytime to evaluate your summarizer.
Datasets
Having to maintain a database to store meeting transcripts might not be feasible and accessing them everytime may also prove to be hard. In such cases, we can use deepeval's datasets.
They are simply a collection of Goldens that can be stored in cloud and pulled anytime with just a few lines of code. They allow you to create test cases during run time by calling your LLM.
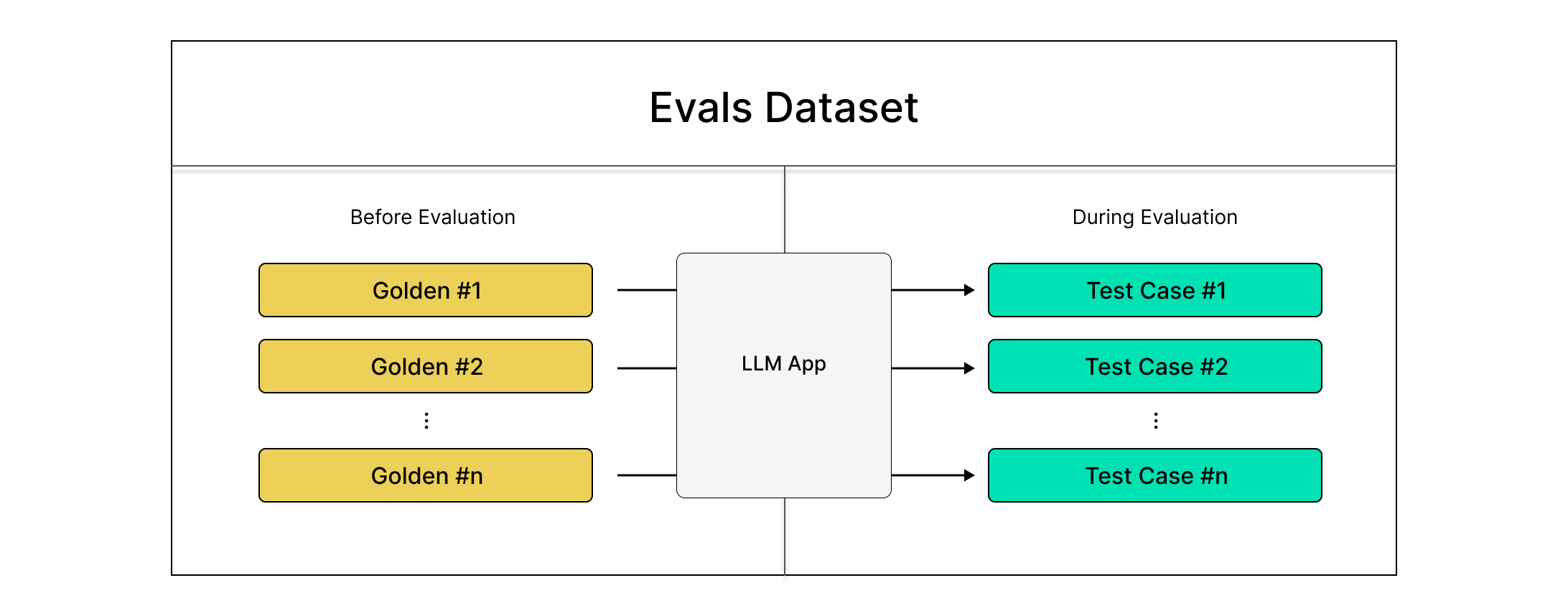
Click here to learn about Golden in DeepEval
A dataset can only be created with a list of goldens. Goldens represent a more flexible alternative to test cases in the deepeval, and it is the preferred way to initialize a dataset using goldens. Unlike test cases, Goldens:
- Don't require an
actual_outputwhen created - Store expected results like
expected_outputandexpected_tools - Serve as templates before becoming fully-formed test cases
Creating Goldens
We can create a dataset that contains numerous goldens each corresponding to different meeting transcripts represented as inputs which can later be used to create LLMTestCases during runtime by calling and filling actual_outputs. Here's how you can create those goldens by looping over transcripts in a folder:
import os
from deepeval.dataset import Golden
documents_path = "path/to/documents/folder"
transcripts = []
for document in os.listdir(documents_path):
if document.endswith(".txt"):
file_path = os.path.join(documents_path, document)
with open(file_path, "r") as file:
transcript = file.read().strip()
transcripts.append(transcript)
goldens = []
for transcript in transcripts:
golden = Golden(
input=transcript
)
goldens.append(golden)You can sanity check your goldens as shown below:
for i, golden in enumerate(goldens):
print(f"Golden {i}: ", golden.input[:20])We can use the above created goldens to initialize a dataset and store it in cloud. Here's how you can do that:
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset(goldens=goldens)
dataset.push(alias="MeetingSummarizer Dataset")✅ Done. We can now move on to creating test cases using this dataset.
Creating Test Cases
We will now call our summarization agent on the dataset inputs and create our LLMTestCases that we can use to evaluate our agent. Since our summarization agent returns summary and action items separately, we will create 2 test cases for 1 summarize() call.
Here's how we can pull our dataset and create test cases:
from deepeval.test_case import LLMTestCase, SingleTurnParams
from deepeval.dataset import EvaluationDataset
from meeting_summarizer import MeetingSummarizer # import your summarizer here
dataset = EvaluationDataset()
dataset.pull(alias="MeetingSummarizer Dataset")
summarizer = MeetingSummarizer() # Initialize with your best config
summary_test_cases = []
action_item_test_cases = []
for golden in dataset.goldens:
summary, action_items = summarizer.summarize(golden.input)
summary_test_case = LLMTestCase(
input=golden.input,
actual_output=summary
)
action_item_test_case = LLMTestCase(
input=golden.input,
actual_output=str(action_items)
)
summary_test_cases.append(summary_test_case)
action_item_test_cases.append(action_item_test_case)✅ Done. We now need to create our metrics to run evaluations on these test cases.
Creating Metrics
Generally LLM applications are evaluated on 1-2 generic criteria and 1-2 use-case specific criteria. The summarization agent we've created processes meeting transcripts and generates a concise summary of the meeting and a list of action items. A generic criteria might not prove as useful on this application. So we'll be going with 2 use case specific criteria:
- The summaries generated must be concise and contain all important points
- The action items generated must be correct and cover all the key actions
From the criterion that we have defined above, both of them are custom criteria that exist only for our use case. Hence, we'll be using a custom metric:
Summary Concision
We will create a custom G-Eval metric with the above defined criteria for summaries generated to be concise. Here's how we can do that:
from deepeval.metrics import GEval
summary_concision = GEval(
name="Summary Concision",
# Write your criteria here
criteria="Assess whether the summary is concise and focused only on the essential points of the meeting? It should avoid repetition, irrelevant details, and unnecessary elaboration.",
threshold=0.9,
evaluation_params=[SingleTurnParams.INPUT, SingleTurnParams.ACTUAL_OUTPUT]
)Action Items Check
We will create a custom metric to check the action items generated. Here's how we can do that:
from deepeval.metrics import GEval
action_item_check = GEval(
name="Action Item Accuracy",
# Write your criteria here
criteria="Are the action items accurate, complete, and clearly reflect the key tasks or follow-ups mentioned in the meeting?",
threshold=0.9,
evaluation_params=[SingleTurnParams.INPUT, SingleTurnParams.ACTUAL_OUTPUT]
)Under-the-hood, the GEval metric uses LLM-as-a-judge with chain-of-thoughts (CoT) to evaluate LLM outputs based on ANY custom criteria.
Running Evals
We can now use the test cases and metrics we created to run our evaluations. Here's how we can run our first eval:
Summary Eval
Since we created separate metrics and separate test cases for our summarizer, we'll first evaluate the summary concision:
from deepeval import evaluate
evaluate(
test_cases=summary_test_cases,
metrics=[summary_concision]
)Action Item Eval
We can run a separate evaluation for action items generated as shown below:
from deepeval import evaluate
evaluate(
test_cases=action_item_test_cases,
metrics=[action_item_check]
)🎉🥳 Congratulations! You've successfully learnt how to evaluate an LLM application. In this example we've successfully learnt how to:
- Create test cases for our summarization agent and evaluate it using
deepeval - Create datasets to store your inputs and use them anytime to generate test cases on-the-fly during run time
You can also run deepeval view to see the results of evals on Confident AI:
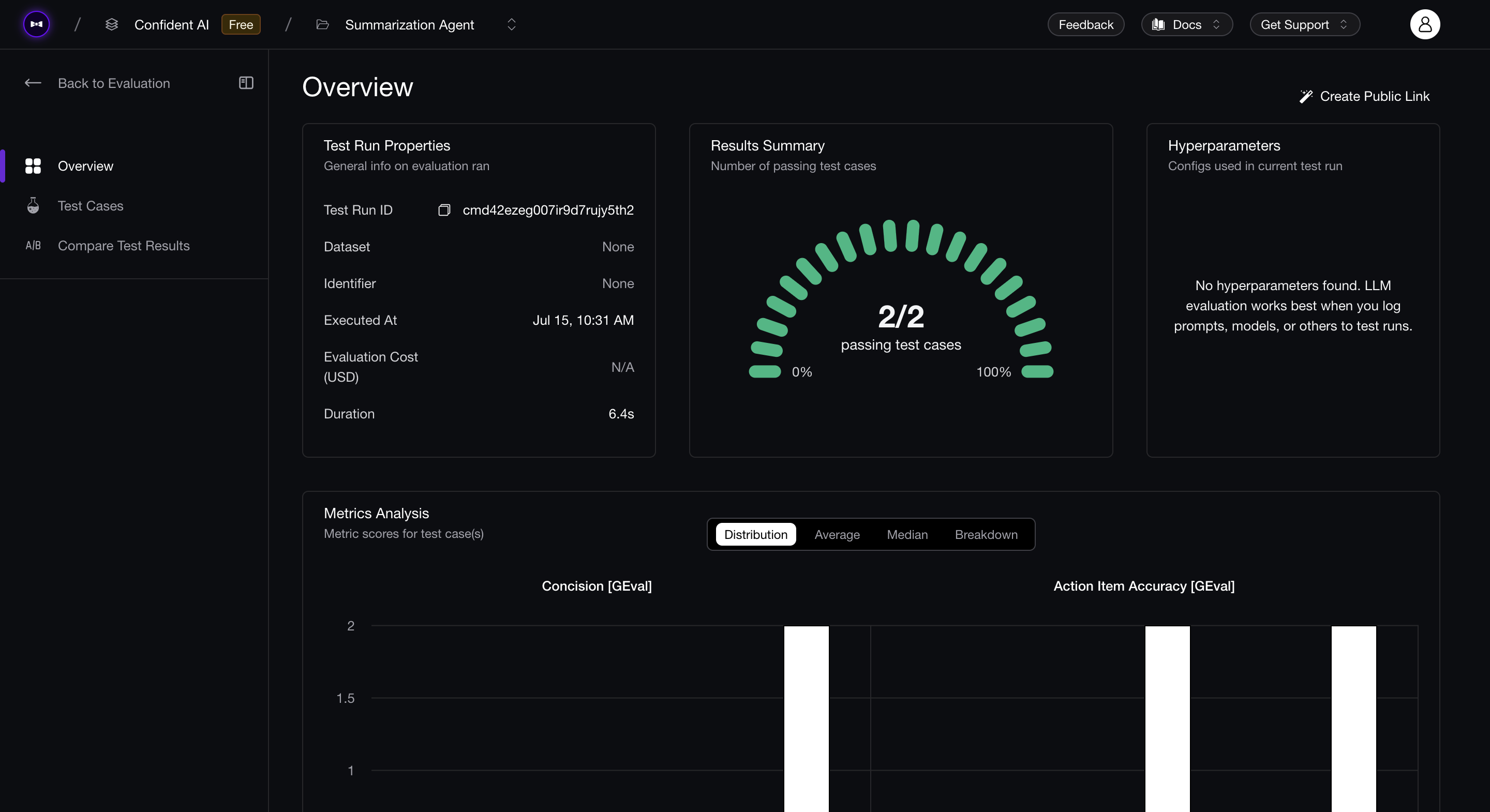
Evaluation Results
DeepEval's metrics provide a reason for their evaluation of a test case, which allows you to debug your LLM application easily on why certain test cases pass or fail. Below is one of the reasons from a failed test case provided by deepeval's GEval for the above evaluations:
For summary:
The Actual Output effectively identifies the key points of the meeting, covering the issues with the assistant's performance, the comparison between GPT-4o and Claude 3, the proposed hybrid approach, and the discussion around confidence metrics and tone. It omits extraneous details and is significantly shorter than the Input transcript. There's minimal repetition. However, while concise, it could be slightly more reduced; some phrasing feels unnecessarily verbose for a summary (e.g., 'Ethan and Maya discussed... focusing on concerns').
For action items:
The Actual Output captures some key action items discussed in the Input, specifically Maya building the similarity metric and setting up the hybrid model test, and Ethan syncing with design. However, it misses several follow-ups, such as exploring 8-bit embedding quantization and addressing the robotic tone of the assistant via prompt tuning. While the listed actions are clear and accurate, the completeness is lacking. The action items directly correspond to tasks mentioned, but not all tasks are represented.
In the next section, we'll see how we can improve our summarization agent using the evaluation results from deepeval