Deployment
In this section, we'll set up CI/CD workflows for your summarization agent, and learn how to manage dynamic datasets to ensure reliable evaluation as your data evolves.
In the previous section, we created a deepeval dataset. You can now reuse this dataset to continuously evaluate your summarization agent.
Why Continuous Evaluation
Most summarization agents are built to summarize documents and transcripts, often to improve productivity. This means that the documents to be summarized are ever-growing, and your summarizer needs to be able to keep up with that. That's why continuous testing is essential — your summarizer must remain reliable, even as new types of documents are introduced.
DeepEval's datasets are very useful for continuous evaluations. You can populate datasets with goldens, which contain just the inputs. During evaluation, test cases are generated on-the-fly by calling your LLM application to produce outputs.
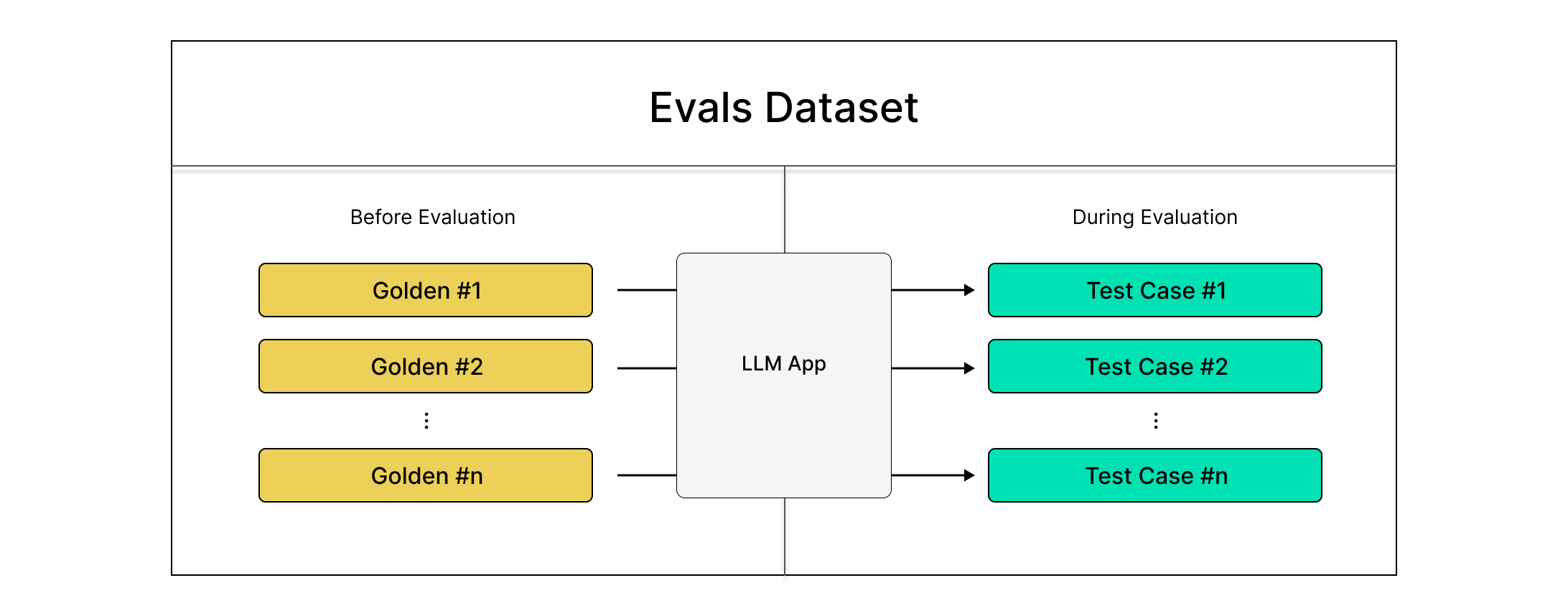
Using Datasets
Here's how you can pull datasets and reuse them to generate test cases:
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
dataset.pull(alias="MeetingSummarizer Dataset")
If you've populated your dataset with goldens, here's how to convert them to test cases:
from deepeval.test_case import LLMTestCase
from meeting_summarizer import MeetingSummarizer # import your summarizer here
summarizer = MeetingSummarizer() # Initialize with your best config
summary_test_cases = []
action_item_test_cases = []
for golden in dataset.goldens:
summary, action_items = summarizer.summarize(golden.input)
summary_test_case = LLMTestCase(
input=golden.input,
actual_output=summary
)
action_item_test_case = LLMTestCase(
input=golden.input,
actual_output=str(action_items)
)
summary_test_cases.append(summary_test_case)
action_item_test_cases.append(action_item_test_case)
print(len(summary_test_cases))
print(len(action_item_test_cases))
Setup Tracing
deepeval offers an @observe decorator for you to apply metrics at any point in your LLM app to evaluate any LLM interaction,
this provides full visibility for debugging internal components of your LLM application. Learn more about tracing here.
To set up tracing, modify your MeetingSummarizer class like this:
import os
import json
from openai import OpenAI
from dotenv import load_dotenv
from deepeval.metrics import GEval
from deepeval.tracing import observe, update_current_span
from deepeval.test_case import LLMTestCase, LLMTestCaseParams
load_dotenv()
class MeetingSummarizer:
def __init__(
self,
model: str = "gpt-4",
summary_system_prompt: str = "",
action_item_system_prompt: str = "",
):
self.model = model
self.client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
self.summary_system_prompt = summary_system_prompt or (
"..." # Use the summary_system_prompt mentioned above
)
self.action_item_system_prompt = action_item_system_prompt or (
"..." # Use the action_item_system_prompt mentioned above
)
@observe(type="agent")
def summarize(
self,
transcript: str,
summary_model: str = "gpt-4o",
action_item_model: str = "gpt-4-turbo"
) -> tuple[str, dict]:
summary = self.get_summary(transcript, summary_model)
action_items = self.get_action_items(transcript, action_item_model)
return summary, action_items
@observe(metrics=[GEval(...)], name="Summary") # Use the summary_concision metric here
def get_summary(self, transcript: str, model: str = None) -> str:
try:
response = self.client.chat.completions.create(
model=model or self.model,
messages=[
{"role": "system", "content": self.summary_system_prompt},
{"role": "user", "content": transcript}
]
)
summary = response.choices[0].message.content.strip()
update_current_span(
test_case=LLMTestCase(input=transcript, actual_output=summary)
)
return summary
except Exception as e:
print(f"Error generating summary: {e}")
return f"Error: Could not generate summary due to API issue: {e}"
@observe(metrics=[GEval(...)], name="Action Items") # Use the action_item_check metric here
def get_action_items(self, transcript: str, model: str = None) -> dict:
try:
response = self.client.chat.completions.create(
model=model or self.model,
messages=[
{"role": "system", "content": self.action_item_system_prompt},
{"role": "user", "content": transcript}
]
)
action_items = response.choices[0].message.content.strip()
try:
action_items = json.loads(action_items)
update_current_span(
test_case=LLMTestCase(input=transcript, actual_output=str(action_items))
)
return action_items
except json.JSONDecodeError:
return {"error": "Invalid JSON returned from model", "raw_output": action_items}
except Exception as e:
print(f"Error generating action items: {e}")
return {"error": f"API call failed: {e}", "raw_output": ""}
Integrating CI/CD
You can use pytest with assert_test during your CI/CD to trace and evaluate your summarization agent, here's how you can write the test file to do that:
import pytest
from deepeval.dataset import EvaluationDataset
from meeting_summarizer import MeetingSummarizer # import your summarizer here
from deepeval import assert_test
dataset = EvaluationDataset()
dataset.pull(alias="MeetingSummarizer Dataset")
summarizer = MeetingSummarizer()
@pytest.mark.parametrize("golden", dataset.goldens)
def test_meeting_summarizer_components(golden):
assert_test(golden=golden, observed_callback=summarizer.summarize)
poetry run pytest -v test_meeting_summarizer_quality.py
Finally, let's integrate this test into GitHub Actions to enable automated quality checks on every push.
name: Meeting Summarizer DeepEval Tests
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
steps:
- name: Checkout Code
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: "3.10"
- name: Install Poetry
run: |
curl -sSL https://install.python-poetry.org | python3 -
echo "$HOME/.local/bin" >> $GITHUB_PATH
- name: Install Dependencies
run: poetry install --no-root
- name: Run DeepEval Unit Tests
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }} # Add your OPENAI_API_KEY
CONFIDENT_API_KEY: ${{ secrets.CONFIDENT_API_KEY }} # Add your CONFIDENT_API_KEY
run: poetry run pytest -v test_meeting_summarizer_quality.py
And that's it! You now have a robust, production-ready summarization agent with automated evaluation integrated into your development workflow.
Setup Confident AI to track your summarization agent's performance across builds, regressions, and evolving datasets. It's free to get started. (No credit card required)
Learn more here.